
Most Influential Data Preprocessing Algorithms
This Website contains additional material to the paper
S. García, J. Luengo, F. Herrera, Tutorial on practical tips of the most influential data preprocessing algorithms in data mining. Knowledge-based Systems 98 (2016) 1-29, doi:10.1016/j.knosys.2015.12.006.
according to the following summary:
- Abstract
- Data preprocessing introduction
- Experimental framework
- Analysis of results
- Software
- Related websites: Data Preprocessing in Data Mining, Big Data, Prototype Selection and Prototype Generation, Missing Values in Data Mining, Noisy Data in Data mining, Classification with Imbalanced data sets, KEEL
You may be also interested in our latest book in Data Preprocessing:
 |
Data Preprocessing in Data Mining |
Abstract
Data preprocessing is a major and essential stage whose main goal is to obtain final data sets that can be considered correct and useful for further data mining algorithms. This paper summarizes the most influential data preprocessing algorithms according to their usage, popularity and extensions proposed in the specialized literature. For each algorithm, we provide a description, a discussion on its impact, and a review of current and further research on it. These most influential algorithms cover missing values imputation, noise filtering, dimensionality reduction (including feature selection and space transformations), instance reduction (including selection and generation), discretization and treatment of data for imbalanced preprocessing. They constitute all among the most important topics in data preprocessing research and development. This paper also presents an illustrative study in two sections with different data sets that provide useful tips for the use of preprocessing algorithms. In the first place, we graphically present the effects on two benchmark data sets for the preprocessing methods. The reader may find useful insights on the different characteristics and outcomes generated by them. Secondly, we use a real world problem presented in the ECDBL'2014 Big Data competition to provide a thorough analysis on the application of some preprocessing techniques, their combination and their performance. As a result, five different cases are analyzed, providing tips that may be useful for readers.
The structure of the paper is as follows:
- Introduction
- Most Influential Data Preprocessing Algorithms
- Imperfect Data
- Missing Values Imputation
- Noise Filtering
- Data Reduction
- Feature Selection
- Space Transformation
- Instance Selection
- Instance Generation. LVQ: Learning Vector Quantization
- Discretization
- Imbalanced Data Preprocessing. SMOTE: Synthetic Minority Over-Sampling Technique
- Imperfect Data
- Practical Usage and Tips I: A Graphical Study with Two Cases of Study, Sonar and Banana Data Sets
- Missing Values Imputation: banana data set
- Noise Filtering: banana data set
- Feature Selection: sonar data set
- Space Transformations: sonar data set
- Instance Reduction: banana data set
- Discretization: banana data set
- Imbalanced Learning with SMOTE: banana data set
- Practical Usage and Tips II: Data Preprocessing Using the ECDBL'2014 Data Mining Competition for Contact Map Prediction
- Conclusions
Data preprocessing introduction
Data preprocessing for Data Mining focuses on one of the most meaningful issues within the famous Knowledge Discovery from Data process. Data will likely have inconsistencies, errors, out of range values, impossible data combinations, missing values or most substantially, data is not suitable to start a DM process. In addition, the growing amount of data in current business applications, science, industry and academia, demands to the requirement of more complex mechanisms to analyze it. With data preprocessing, converting the impractical into possible is achievable, adapting the data to accomplish the input requirements of each DM
algorithm.
The data preprocessing stage can take a considerable amount of processing time. Data preprocessing includes data preparation, compounded by integration, cleaning, normalization and transformation of data; and data reduction tasks, which aim at reducing the complexity of the data, detecting or removing irrelevant and noisy elements from the data through feature selection, instance selection or discretization processes. The outcome expected after a reliable connection of data preprocessing processes is a final data set, which can be contemplated correct and useful for further DM algorithms.
In an effort to identify some of the most influential data preprocessing algorithms that have been widely used in the DM community, we enumerate them according to their usage, popularity and extensions proposed in the research community. We are aware that each
nominated algorithm should have been widely cited and used by other researchers and practitioners in the eld. The selection of the algorithms is based entirely on our criteria and expertise, and it is summarized in the following figure according to their category.
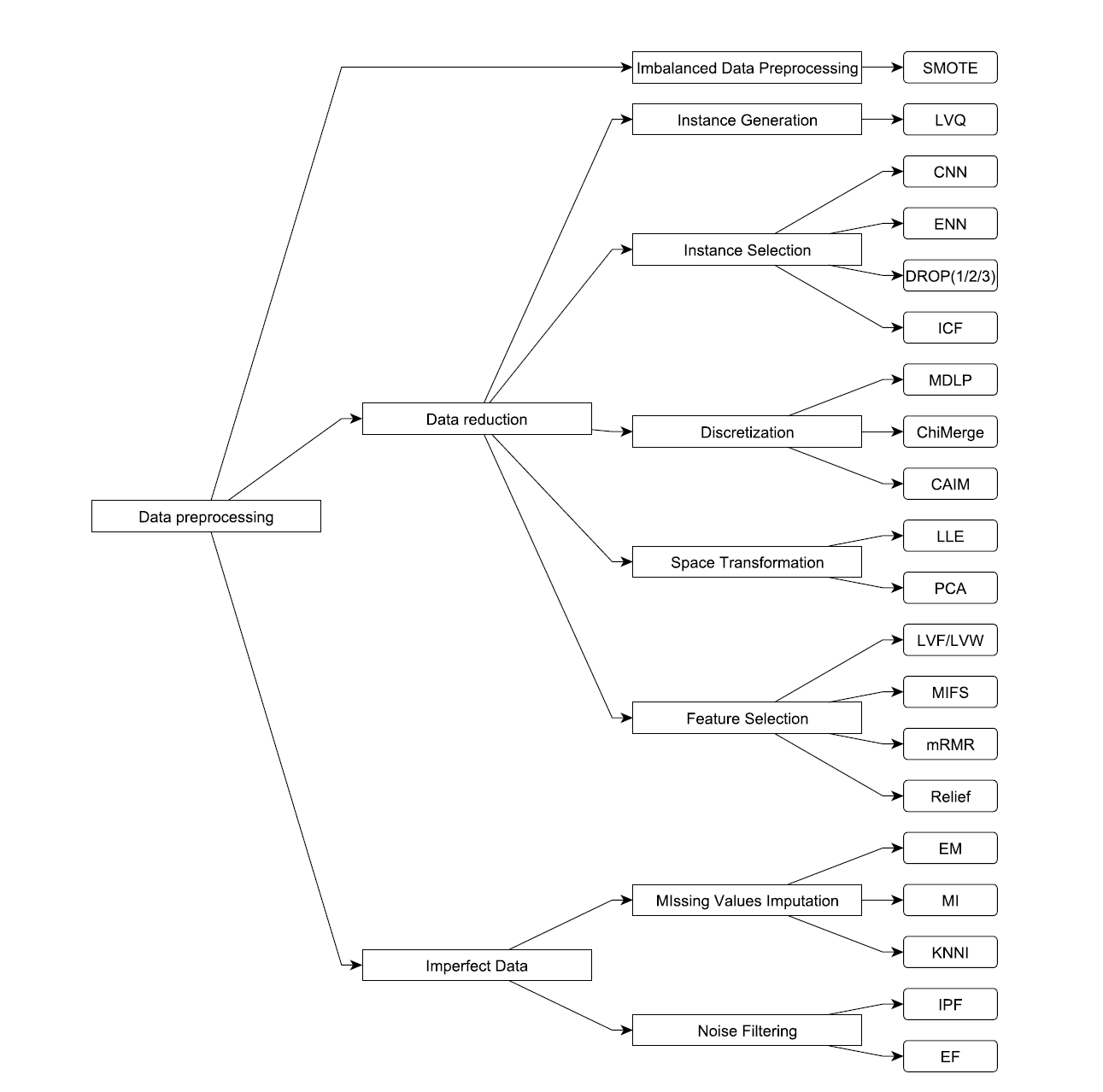
The references of such algorithms follows.
| Acronym | Reference |
|---|---|
| EF | C.E. Brodley, M.A. Friedl, Identifying Mislabeled Training Data, Journal of Artificial Intelligence Research 11 (1999) 131{167. |
| IPF | T.M. Khoshgoftaar, P. Rebours, Improving software quality prediction by noise ltering techniques, Journal of Computer Science and Technology 22 (2007) 387-396. |
| KNNI | G. Batista, M. Monard, An analysis of four missing data treatment methods for supervised learning, Applied Artificial Intelligence 17 (2003) 519-533. |
| EM |
A. Dempster, N. Laird, D. Rubin, Maximum likelihood estimation from incomplete data via the EM algorithm (with discussion), Journal of the Royal Statistical Society, Series B 39 (1977) 1-38. R.J.A. Little, D.B. Rubin, Statistical Analysis with Missing Data, Wiley Series in Probability and Statistics, Wiley, New York, 1st edition, 1987. |
| MI | D.B. Rubin, Multiple Imputation for Nonresponse in Surveys, Wiley, 1987. |
| Relief | K. Kira, L.A. Rendell, A practical approach to feature selection, in: Proceedings of the Ninth International Workshop on Machine Learning, ML92, 1992, pp. 249-256. |
| mRMR | H. Peng, F. Long, C. Ding, Feature selection based on mutual information: Criteria of maxdependency, max-relevance, and min-redundancy, IEEE Transactions on Pattern Analysis and Machine Intelligence 27 (2005) 1226-1238. |
| MIFS | R. Battiti, Using mutual information for selection features in supervised neural net learning, IEEE Transactions on Neural Networks 5 (1994) 537-550. |
| LVF/LVW | H. Liu, R. Setiono, A probabilistic approach to feature selection - a lter solution, in: Proceedings of the International Conference on Machine Learning (ICML), 1996, pp. 319-327. |
| PCA | G. Dunteman, Principal Components Analysis, A Sage Publications, SAGE Publications, 1989. |
| LLE | S. Roweis, L. Saul, Nonlinear dimensionality reduction by locally linear embedding, Science 290 (2000) 2323-2326. |
| CAIM | L.A. Kurgan, K.J. Cios, CAIM discretization algorithm, IEEE Transactions on Knowledge and Data Engineering 16 (2004) 145{153. |
| ChiMerge | R. Kerber, Chimerge: Discretization of numeric attributes, in: National Conference on Arti cal Intelligence American Association for Artificial Intelligence (AAAI), 1992, pp. 123{128. |
| MDLP | U.M. Fayyad, K.B. Irani, Multi-interval discretization of continuous-valued attributes for classification learning, in: Proceedings of the 13th International Joint Conference on Arti cial Intelligence (IJCAI), 1993, pp. 1022-1029. |
| ICF | H. Brighton, C. Mellish, Advances in instance selection for instance-based learning algorithms, Data Mining and Knowledge Discovery 6 (2002) 153-172. |
| DROP | D.R. Wilson, T.R. Martinez, Reduction techniques for instance-based learning algorithms, Machine Learning 38 (2000) 257{286. |
| ENN | D.L. Wilson, Asymptotic properties of nearest neighbor rules using edited data, IEEE Transactions on System, Man and Cybernetics 2 (1972) 408-421. |
| CNN | P.E. Hart, The condensed nearest neighbor rule, IEEE Transactions on Information Theory 14 (1968) 515-516. |
| LVQ | T. Kohonen, The self-organizing map, Proceedings of the IEEE 78 (1990) 1464-1480. |
| SMOTE | N.V. Chawla, K.W. Bowyer, L.O. Hall, W.P. Kegelmeyer, SMOTE: synthetic minority over-sampling technique, Journal of Arti cial Intelligence Research 16 (2002) 321{357. |
Experimental framework
Two data sets have been used to graphically illustrate the effect of preprocessing techniques:
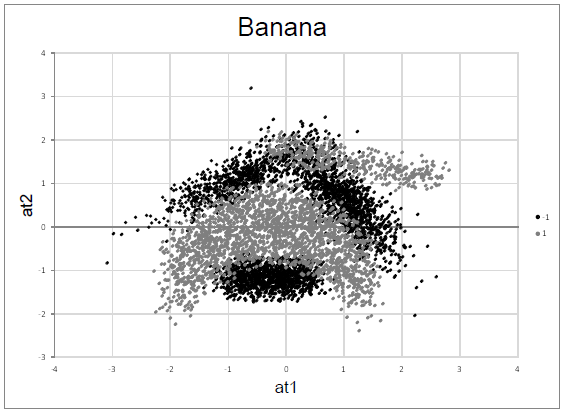
- banana data set: is a synthetic data set with 5,300 instances, 2 classes and 2 input attributes, which makes it specially well suited to be represented in a plane. As can be seen in the following figure, the classes are not linearly separable, conforming to a "banana" shaped cluster with overlapping between the classes.
- sonar data set: is a real-world data set with 208 instances, 60 real-valued input attributes and 2 classes. Since FS and dimensionally reduction techniques need a large number of input attributes to be useful, we will only use the sonar data set for them.
- ECDBL14-20000-N-MV data set: is a a reduced sample from the ECDBL'14 Data mining competition (Data mining competition 2014: Self-deployment track (2014): Evolutionary computation for big data and big learning workshop, 2014, http://cruncher.ncl.ac.uk/bdcomp/) to a sample with a training fold with 20,000 instances containing MVs and noise. It is coupled with a test set with 20,000 instances. This reduced data set has 50 input attributes (real, integer and nominal valued), with 75% instances of the negative class and 25% instances of the positive class.
In the following table we provide the data sets used for the experiments in KEEL format.
| Banana | |
| Sonar | |
| ECDBL14-20000-N-MV - training partition | |
| ECDBL14-20000-N-MV - test partition |
Analysis of results
Practical Usage and Tips I: A Graphical Study with Two Cases of Study,
Sonar and Banana Data Sets
In this section we want to show the effect and utility of the selected preprocessing algorithms. Our goal is also to graphically illustrate the e ect of such techniques, so the reader can visually determine the differences among them by visualizing how they work through graphical representations.
In order to do so, the banana and sonar data sets will be used. Noise, imbalance or missing values are artificially introduced in the sonar data set to enable the usage of imputation and filters. For those techniques aimed to reduce the dimensionality, the sonar data set is used instead.
The resulting data sets after applying preprocessing and their depictions are available in the following links.
| Preprocessing type | 2D Figure | Data set in KEEL format |
Missing values (Banana data set)We have introduced a 10% of missing values (MVs) in the data set. Then imputation methods (KNNI, EM and MI) are used to estimate them. |
|
|
Noise (Banana data set)
We have introduced a 10% of noise in the data set. |
|
|
Feature selection (Sonar data set)Several feature selection methods are used to reduce the dimensionality of the sonar data set. To facilitate the visualization of the resulting data sets, PCA is applied in order to obtain a 2D projection of them. |
|
|
Space transformations (Sonar data set)We apply PCA and LLE to transform the sonar data set to a 2D transformed version. |
|
|
Instance reduction (Banana data set)We use several instance selection algorithms to reduce the number of instances of the banana data set. |
|
|
Imbalanced learning (Banana data set)First we apply Random Undersampling (RUS) to create an imbalanced version of the banana data set. Then SMOTE is used to balance the class distribution, generating synthetic examples of the minority class.
|
|
Practical Usage and Tips II: Data Preprocessing Using the ECDBL14-20000-N-MV
In this section we illustrate how the use and combination of some the most popular preprocessing methods over a single, large real-world data set can improve the results obtained by a well-known DM algorithm. Our goal is to show how the order in which preprocessingis applied can vastly influence the results, and also how the parameters' adjustment can be beneficial as well.
In order to carry out the analysis, we will use the ECDBL14-20000-N-MV data set with missing values, noise and an imbalanced class distribution. We have selected one preprocessing algorithm of each type to be applied to this data set:
- an imputation method (kNNI),
- a noise ltering algorithm (IPF),
- a FS method (LVW),
- an instance selector (ENN) and
- the over-sampling algorithm for imbalanced data sets (SMOTE).
The parameters used for each preprocessing technique vary depending on which scenario is selected among the 5 described in the paper and that are shown next (indicating the final AUC value obtained for each scenario in the leaves):
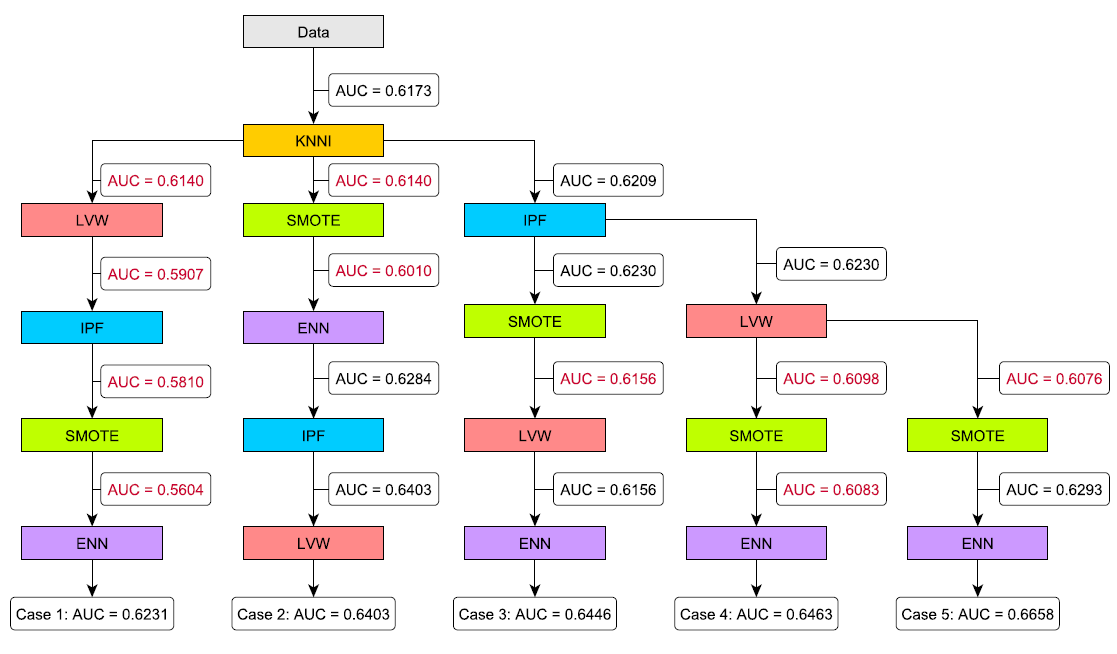
As we can appreciate from the different cases, the order in which the preprocessing techniques are applied has a large impact in the final result. It is also important to notice that some preprocessing techniques may seem counterproductive at first glance, but they
will finally yield a benefit when combined with others.
The reader must then take into account that modifying the parameters of a preprocessing algorithm will have influence in the rest of techniques applied afterwards, not only in the proper step. Thus, optimizations for a particular preprocessing technique's parameters must be checked along all the preprocessing chain and not individually in each step.
The final resulting training sets of the ECDBL14-20000-N-MV training partition after applying the preprocessing can be obtained in the following. Please note that these training sets must be used to train a model, and the reader must use the test partition to obtain the performance measure. Each branch of the figure shown above is denoted as Case 1 to 5.
| Case 1 | Case 2 | Case 3 | Case 4 | Case 5 |
Software
The algorithms described in the paper are implemented and publicly available in several software tools. Here we summarize these software packages to enable the practitioner to freely use them:
- KEEL. Most of the algorithms presented are already included in this open source Data Mining tool.
- Weka is another well-known open source Data Mining tool, whose PCA implementation is used here.
- Orange
- Knime
- mRMR implementation and also an online tool to remotely apply mRMR to your data. Source code of mRMR is also available directly from the authors.
- LLE homepage, with examples and MATLAB source code from the authors.
Related websites: Data Preprocessing in Data Mining, Big Data, Prototype Selection and Prototype Generation, Missing Values in Data Mining, Noisy Data in Data mining, Classification with Imbalanced data sets, KEEL
You may also find specialized websites in our webpage devoted and related to preprocessing tasks as:

