
Prototype Reduction in Nearest Neighbor Classification: Prototype Selection and Prototype Generation
This Website contains SCI2S research material on Prototype Reduction in Nearest Neighbor Classification. This research is related to the following SCI2S surveys published recently: 
- S. García, J. Derrac, J.R. Cano and F. Herrera, Prototype Selection for Nearest Neighbor Classification: Taxonomy and Empirical Study. IEEE Transactions on Pattern Analysis and Machine Intelligence 34:3 (2012) 417-435 doi: 10.1109/TPAMI.2011.142
 COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes.
COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes. - I. Triguero, J. Derrac, S. García and F. Herrera, A Taxonomy and Experimental Study on Prototype Generation for Nearest Neighbor Classification . IEEE Transactions on Systems, Man, and Cybernetics--Part C: Applications and Reviews 42:1 (2012) 86-100, doi: 10.1109/TSMCC.2010.2103939 COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes.
The web is organized according to the following Summary:
- Introduction to Prototype Reduction
- Prototype Selection
- Prototype Generation
- Prototype Reduction Outlook
Introduction to Prototype Reduction
Nowadays, the amount of data which scientific, research and industry processes must handle has increased substantially. The original capabilities of most of Data Mining techniques have been exceeded by the incoming data deluge. However, several tools have been developed to deal with this issue, easing the drawbacks of using an overwhelming amount of data to feed the Data Mining processes.
Data Reduction (D.Pyle, Data Preparation for Data Mining, Morgan Kaufmann, San Francisco (1999).) techniques arise as methods for minimizing the impact of huge data sets in the behavior of algorithms, reducing the size of the data without harming the quality of the intrinsic knowledge stored initially. That is, data handling requirements are reduced whereas the predictive capability of the algorithms is maintained.
The K-Nearest Neighbors classifier (KNN) (T.M. Cover, P.E. Hart, Nearest Neighbor Pattern Classification. IEEE Transactions on Information Theory 13 (1967) 21–27. doi: 10.1109/TIT.1967.1053964) is probably one of the most benefited algorithms from Data Reduction techniques. Although it is one of the most popular algorithms in Machine Learning (X. Wu and V. Kumar, Eds. , The Top Ten Algorithms in Data Mining. Chapman & Hall/CRC, Data Mining and Knowledge Discovery (2009).), mainly due to its simplicity, and overall good performance, the KNN suffers from several drawbacks related to the size of the training set. In order to avoid, or, at least, ease these drawbacks, several Data Reduction techniques have been sucessfully applied for enhancing the behavior of this algorithm, including Feature Selection (H. Liu, H. Motoda (Eds.) , Computational Methods of Feature Selection, Chapman & Hall, CRC, London, Boca Raton (2007).), Instance Selection (H. Liu, H. Motoda (Eds.), Instance Selection and Construction for Data Mining, Springer, New York (2001).) or Feature Discretization (H. Liu, F. Hussain, C. Lim, M. Dash, Discretization: An Enabling Technique. Data Mining and Knowledge Discovery 6:4 (2002) 393-423. doi: 10.1023/A:1016304305535).
Instance-Based Learning algorithms (D. W. Aha, D. F. Kibler, M. K. Albert: Instance-Based Learning Algorithms. Machine Learning 6 (1991) 37-66. doi: 10.1023/A:1022689900470), such as the KNN, rely heavily in the quality of the instances stored as training data. The memory requirements, time complexity and accuracy of the classifier can be affected substantially if the initial data is preprocessed in a smart way: the removal or correction of noisy instances will enhance the generalization capabilities of the algorithm, whereas the deletion of redundant or irrelevant examples will reduce the computational time and the amount of memory needed to run the classifier.
The first attempts to incorporate the notion of prototypes to the KNN realm were focused in the reduction of the original data. By condensing the examples that make up the training set (P. E. Hart, The Condensed Nearest Neighbor Rule. IEEE Transactions on Information Theory 18 (1968) 515–516. doi: 10.1109/TIT.1968.1054155), or by deleting noisy instances (D. L. Wilson, Asymptotic Properties of Nearest Neighbor Rules Using Edited Data. IEEE Transactions on System, Man and Cybernetics 2:3 (1972) 408–421. doi: 10.1109/TSMC.1972.4309137), the first Prototype Selection methods starting to arouse the attention of many researchers and practitioners as years went by.
On the other hand, Prototype Generation arise as a way to generate new data from the starting training set, aiming to be best suited to represent the domain of the problem. Prototype Generation methods often work by modifying the position or the label of the original instances, or by generating new ones. The resulting training sets are kept small, thus obtaining time and memory enhancements comparable to those provided by Prototype Selection Methods.
In this website, we provide and outlook of the Prototype Selection and Prototype Generation fields, merged together as Prototype Reduction techniques. Background information, taxonomies and method's references are given, as well as a full set of experimental results obtained through the application of the techniques over a set of well-known supervised classification problems. SCI2S contributions in both fields are also outlined.
In addition, we also provide an outlook of the Prototype Reduction field, describing the most important milestones in its development. Related approaches and outstanding evolutionary proposals are highlighted. Finally, the outlook is concluded with a Visibility analysis of the area at the Web of Science (WoS).
Prototype Selection
Background
Prototype Selection methods (S. García, J. Derrac, J.R. Cano and F. Herrera, Prototype Selection for Nearest Neighbor Classification: Taxonomy and Empirical Study. IEEE Transactions on Pattern Analysis and Machine Intelligence 34:3 (2012) 417-435. doi: 10.1109/TPAMI.2011.142) are Instance Selection methods which expect to find training sets offering best classification accuracy by using the KNN classifier. Thus, their goal is to isolate the smallest set of instances which enable a data mining algorithm to predict the class of a query instance with the same quality as the initial data set. By minimizing the data set size, it is possible to reduce the space complexity and decrease the computational cost of the Data Mining algorithms that will be applied later, improving their generalization capabilities through the elimination of noise.
They can be formally specified as follows: Let Xp be an instance where $X_p = (X_{p1}, X_{p2}, ... , X_{pm}, X_{pc})$, with Xp belonging to a class c given by $X_{pc}$, and a m-dimensional space in which $X_{pi}$ is the value of the i-th feature of the p-th sample. Then, let us assume that there is a training set TR which consists of N instances, and a test set TS composed of T instances. Let S ⊆ TR be the subset of selected samples that resulted from the execution of a Prototype Selection algorithm, then new patterns T from TS can be classified by the KNN acting only over the instances of S.
Therefore, Prototype Selection methods select a subset of examples from the original training data. Depending on the strategy followed, they can be categorized in three classes: preservation methods, which aim to obtain a consistent subset from the training data, ignoring the presence of noise; noise removal methods, which aim to remove noise both in the boundary points (instances near to the decision boundaries) and in the inner points (instances far from the decision boundaries), and hybrid methods, which perform both objectives simultaneously.
Evolutionary Computation (A. Ghosh, L. C. Jain (Eds), Evolutionary Computation in Data Mining. Springer-Verlag, New York (2005)) has emerged among the extensive range of fields which have been producing Prototype Selection model in these years. It has become a outstanding methodology for the definition of new Prototype Selection approaches, redefining the Prototype Selection problem itself as a binary optimization problem (J. R. Cano, F. Herrera, M. Lozano, Using Evolutionary Algorithms as Instance Selection for Data Reduction in KDD: an Experimental Study. IEEE Transactions on Evolutionary Computation 7:6 (2003) 561–575. doi: 10.1109/TEVC.2003.819265). In this way, the Evolutionary Computation has contributing with some methods that excels both in the accuracy enhancement of the KNN and in the reduction of its computational cost.
As years goes by, more Prototype Selection methods are developed with objective of improving the performance of the former approaches. Improvements in storage reduction, noise tolerance, generalization accuracy and time requirements are reported still nowadays. They have become a proof of the lively character of this field, which continues to attracting the interest of many researching communities in the search of new ways to further improve the performance of the KNN classifier.
Taxonomy
The Prototype Selection taxonomy is oriented to categorize the algorithms regarding three aspects related to their operation:
- Direction of Search: It refers to the directions in which the search can proceed: Incremental, decremental, batch, mixed or fixed.
- Type of selection: This factor is mainly conditioned by the type of search carried out by the algorithms, whether they seek to retain border points, central points or some other set of points. The categories defined here are: Condensation, edition and hybrid.
- Evaluation of Search: The third criteria relates to the way in which each step of the search is evaluated. Usually, the objective pursued is to make a prediction on a non-definitive selection and to compare between selections. This characteristic influences the quality criterion and it can be divided into two categories: Fixed and Wrapper
Figure 1 shows a map of the taxonomy, categorizing all the Prototype Selection methods described in this website. Later, they will be described and referenced.
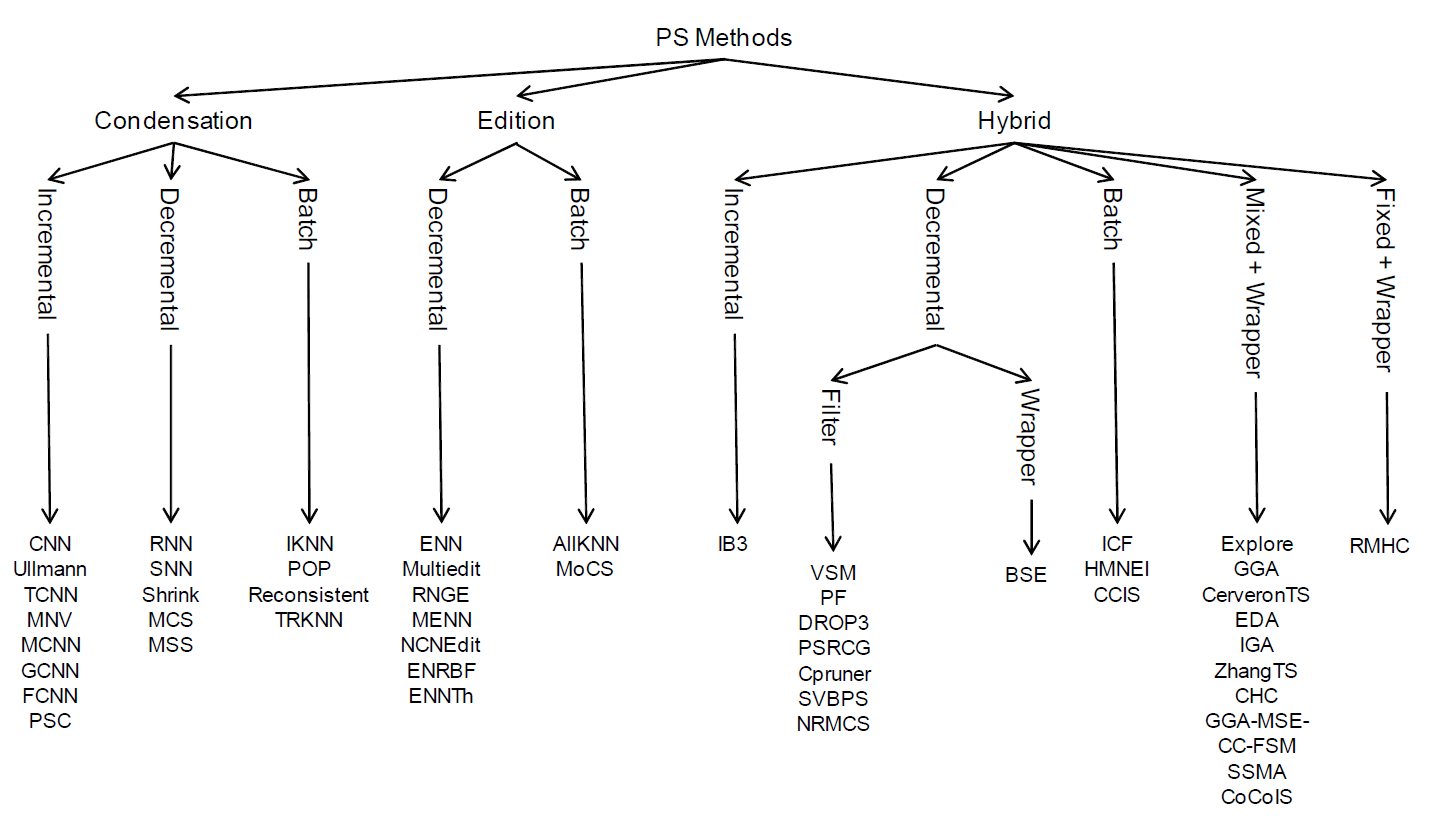
Figure 1. Prototype Selection Taxonomy
The features that define each category are shown as follows:
- Direction of Search
- Incremental: An incremental search begins with an empty subset S, and adds each instance in TR to S if it fulfills some criteria. In this case, the algorithm depends on the order of presentation and this factor could be very important. Under such a scheme, the order of presentation of instances in TR should be random because by definition, an incremental algorithm should be able to handle new instances as they become available without all of them being present at the beginning. Nevertheless, some recent incremental approaches are order-independent because they add instances to S in a somewhat incremental fashion, but they examine all available instances to help select which instance to add next. This makes the algorithm not truly incremental as we have defined above, although we will also consider them as incremental approaches.
One advantage of an incremental scheme is that if instances are made available later, after training is complete, they can continue to be added to S according to the same criteria. This capability could be very helpful when dealing with data streams or online learning. Another advantage is that they can be faster and use less storage during the learning phase than non-incremental algorithms. The main disadvantage is that incremental algorithms must make decisions based on little information and are therefore prone to errors until more information is available.
- Decremental: The decremental search begins with S = TR, and then searches for instances to remove from S. Again, the order of presentation is important, but unlike the incremental process, all of the training examples are available for examination at any time.
One disadvantage with the decremental rule is that it presents a higher computational cost than incremental algorithms. Furthermore, the learning stage must be done in an off-line fashion because decremental approaches need all possible data. However, if the application of a decremental algorithm can result in greater storage reduction, then the extra computation during learning (which is done just once) can be well worth the computational savings during execution thereafter.
- Batch: Another way to apply a Prototype Selection process is in batch mode. This involves deciding if each instance meets the removal criteria before removing any of them. Then all those that do meet the criteria are removed at once. As with decremental algorithms, batch processing suffers from increased time complexity over incremental algorithms.
- Mixed: A mixed search begins with a pre-selected subset S (randomly or selected by an incremental or decremental process) and iteratively can add or remove any instance which meets the specific criterion. This type of search allows rectifications to already done operations and its main advantage is to make easy to obtain good accuracy-suited subsets of instances. It usually suffers from the same drawbacks reported in decremental algorithms, but this fact depends to a great extent on the specific proposal. Note that these kinds of algorithms are closely related to the order-independent incremental approaches but, in this case, instance removal from S is allowed.
- Fixed: A fixed search is a subfamily of mixed search in which the number of additions and removals remains the same. Thus, the number of final prototypes is determined at the beginning of the learning phase and is never changed. This strategy of search is not very common in Prototype Selection, although it is typical in Prototype Generation methods, such as LVQ.
- Incremental: An incremental search begins with an empty subset S, and adds each instance in TR to S if it fulfills some criteria. In this case, the algorithm depends on the order of presentation and this factor could be very important. Under such a scheme, the order of presentation of instances in TR should be random because by definition, an incremental algorithm should be able to handle new instances as they become available without all of them being present at the beginning. Nevertheless, some recent incremental approaches are order-independent because they add instances to S in a somewhat incremental fashion, but they examine all available instances to help select which instance to add next. This makes the algorithm not truly incremental as we have defined above, although we will also consider them as incremental approaches.
- Type of Selection
- Condensation: This set includes the techniques which aim to retain the points which are closer to the decision boundaries, also called border points. The intuition behind retaining border points is that internal points do not affect the decision boundaries as much as border points, and thus can be removed with relatively little effect on classification. The idea behind these methods is to preserve the accuracy over the training set, but the generalization accuracy over the test set can be negatively affected. Nevertheless, the reduction capability of condensation methods is normally high due to the fact that there are fewer border points than internal points in most of the data.
- Edition: These kinds of algorithms instead seek to remove border points. They remove points that are noisy or do not agree with their neighbors. This removes close border points, leaving smoother decision boundaries behind. However, such algorithms do not remove internal points that do not necessarily contribute to the decision boundaries. The effect obtained is related to the improvement of generalization accuracy in test data, although the reduction rate obtained is lower.
- Hybrid: Hybrid methods try to find the smallest subset S which maintains or even increases the generalization accuracy in test data. To achieve this, it allows the removal of internal and border points based on criteria followed by the two previous strategies. The kNN classifier is highly adaptable to these methods, obtaining great improvements even with a very small subset of instances selected.
- Evaluation of Search
- Filter: When the KNN rule is used for partial data to determine the criteria of adding or removing and no leave-one-out validation scheme is used to obtain a good estimation of generalization accuracy. The fact of using subsets of the training data in each decision increments the efficiency of these methods, but the accuracy may not be enhanced.
- Wrapper: When the KNN rule is used for the complete training set with the leave-one-out validation scheme. The conjunction in the use of the two mentioned factors allows us to get a great estimator of generalization accuracy, which helps to obtain better accuracy over test data. However, each decision involves a complete computation of the kNN rule over the training set and the learning phase can be computationally expensive.
Prototype Selection Methods
The Prototype Selection field has provided a remarkable quantity of approaches over the last forty years. Figure 2 depicts the evolution of the area, showing the year of publication of each method. Since the methods are gathered regarding their place in the taxonomy, this map also allows to observe the differences in the growth of each of the sub-areas.
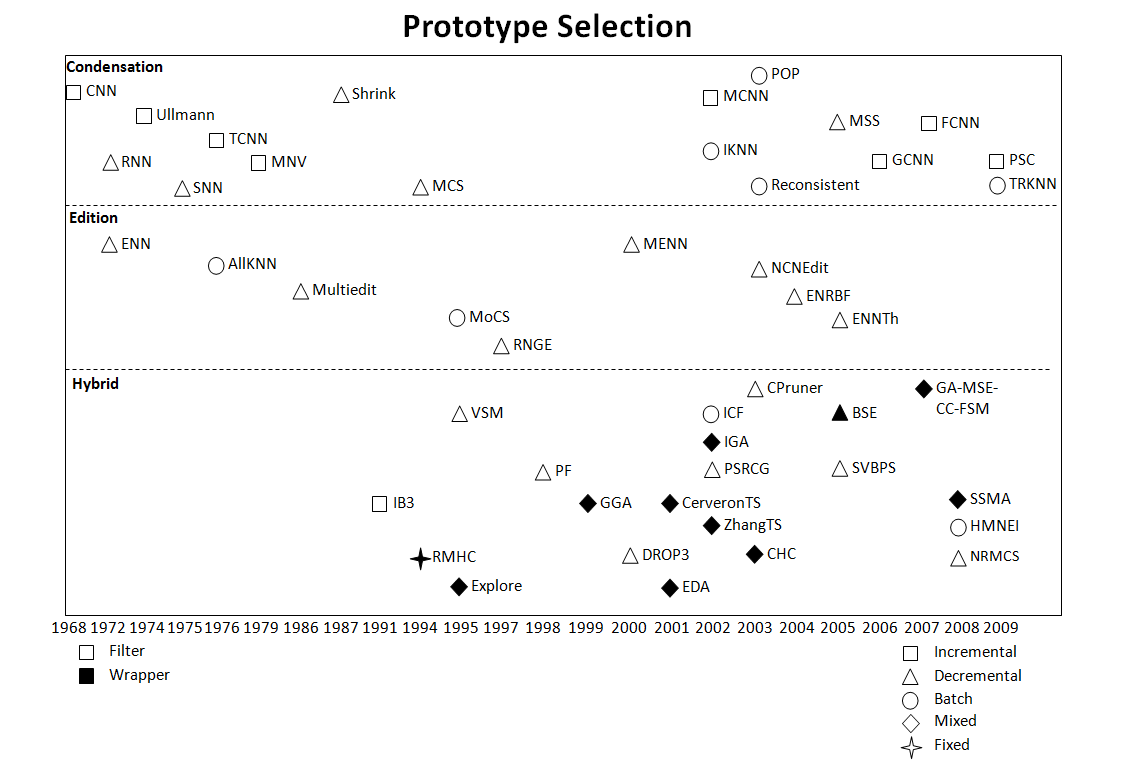
Figure 2. Evolution map of the Prototype Selection field
Each dot considered in the map represent a significant contribution in the area. More details about them can be found in the SCI2S technical report about Prototype Selection methods:
S. García, J. Derrac, J.R. Cano and F.Herrera, Prototype Selection for Nearest Neighbor Classification: Survey of Methods. ![]()
References of the methods (by year of publishing)
- 1968
- Condensed Nearest Neighbor (CNN)
P. E. Hart, The Condensed Nearest Neighbor Rule. IEEE Transactions on Information Theory 18 (1968) 515–516, doi: 10.1109/TIT.1968.1054155
- Condensed Nearest Neighbor (CNN)
- 1972
- Reduced Nearest Neighbor (RNN)
G. W. Gates, The Reduced Nearest Neighbor Rule. IEEE Transactions on Information Theory 22 (1972) 431–433, doi: 10.1109/TIT.1972.1054809
- Edited Nearest Neighbor (ENN)
D. L. Wilson, Asymptotic Properties of Nearest Neighbor Rules Using Edited Data. IEEE Transactions on System, Man and Cybernetics 2:3 (1972) 408–421, doi: 10.1109/TSMC.1972.4309137
- Reduced Nearest Neighbor (RNN)
- 1974
- Ullmann's method (Ullman)
J. R. Ullmann, Automatic Selection of Reference Data for Use in a Nearest-Neighbor Method of Pattern Classification. IEEE Transactions on Information Theory 24 (1974) 541–543, doi: 10.1109/TIT.1974.1055252
- Ullmann's method (Ullman)
- 1975
- Selective Nearest Neighbor (SNN).
G. L. Ritter, H. B. Woodruff, S. R. Lowry, T. L. Isenhour, An Algorithm for a Selective Nearest Neighbor Decision Rule. IEEE Transactions on Information Theory 25 (1975) 665–669, doi: 10.1109/TIT.1975.1055464
- Selective Nearest Neighbor (SNN).
- 1976
- Repeated Edited Nearest Neighbor (RENN).
- All-Knn method (AllKNN).
I. Tomek, An Experiment with the Edited Nearest-Neighbor Rule. IEEE Transactions on Systems, Man, and Cybernetics 6:6 (1976) 448–452, doi: 10.1109/TSMC.1976.4309523
- Tomek Condensed Nearest Neighbor (TCNN)
I. Tomek, Two Modifications of CNN. IEEE Transactions on Systems, Man, and Cybernetics 6:6 (1976) 769–772, doi: 10.1109/TSMC.1976.4309452
- 1979
- Mutual Neighborhood Value (MNV)
K. C. Gowda, G. Krishna, The Condensed Nearest Neighbor Rule Using the Concept of Mutual Nearest Neighborhood. IEEE Transactions on Information Theory 29 (1976) 488–490, doi: 10.1109/TIT.1979.1056066
- Mutual Neighborhood Value (MNV)
- 1982
- MultiEdit (MultiEdit)
P. A. Devijver, J. Kittler, Pattern Recognition, A Statistical Approach. Prentice Hall (1982).
P. A. Devijver, On the Editing Rate of the Multiedit Algorithm. Pattern Recognition Letters 4:1 (1986) 9–12, doi: 10.1016/0167-8655(86)90066-8
- MultiEdit (MultiEdit)
- 1987
- Shrink (Shrink)
D. Kibler, D. W. Aha. Learning Representative Exemplars of Concepts: An initial case study. Proceedings of the Fourth International Workshop on Machine Learning (1987)24–30 .
- Shrink (Shrink)
- 1991
- Instance Based 2 (IB2)
- Instance Based 3 (IB3)
D. W. Aha, D. Kibler, M. K. Albert. Instance-Based Learning Algorithms. Machine Learning 6:1 (1991) 37–66, doi: 10.1023/A:1022689900470
- 1994
- Monte Carlo 1 (MC1)
- Random Mutation Hill Climbing (RMHC)
D. B. Skalak, Prototype and Feature Selection by Sampling and Random Mutation Hill Climbing Algorithms. Proceedings of the Eleventh International Conference on Machine Learning (1994) 293–301 .
- Minimal consistent set (MCS)
B. V. Dasarathy, Minimal Consistent Set (MCS) Identification for Optimal Nearest Neighbor Decision System Design. IEEE Transactions on Systems, Man and Cybernetics 24:3 (1994) 511–517, doi: 10.1109/21.278999
- 1995
- Encoding Lenght Heuristic (ELH)
- Encoding Lenght Growth (ELGrowth)
- Explore (Explore)
R. M. Cameron-Jones, Instance Selection by Encoding Length Heuristic with Random Mutation Hill Climbing. Proceedings of the Eighth Australian Joint Conference on Artificial Intelligence (1995) 99–106.
- Model Class Selection (MoCS)
C. E. Brodley, Recursive Automatic Bias Selection for Classifier Construction. Machine Learning 20:1-2 (1995) 63–94, doi: 10.1007/BF00993475
- Variable Similarity Metric (VSM)
D. G. Lowe, Similarity Metric Learning for a Variable-Kernel Classifier. Neural Computation 7:1 (1995) 72–85, doi: 10.1162/neco.1995.7.1.72
- Generational Genetic Algorithm (GGA)
L. I. Kuncheva, Editing for the K-Nearest Neighbors Rule by a Genetic Algorithm. Pattern Recognition Letters 16:8 (1995) 809–814, doi: 10.1016/0167-8655(95)00047-K
L. I. Kuncheva, L. C. Jain, Nearest Neighbor Classifier: Simultaneous Editing and Feature Selection. Pattern Recognition Letters 20:11-13 (1999) 1149–1156, doi: 10.1016/S0167-8655(99)00082-3
- 1997
- Gabriel Graph Editing (GGE)
- Relative Neighborhood Graph Editing (RNGE)
J. S. Sánchez, F. Pla, F. J. Ferri, Prototype Selection for the Nearest Neighbor Rule Through Proximity Graphs. Pattern Recognition Letters 18 (1997) 507–513, doi: 10.1016/S0167-8655(97)00035-4
- 1998
- Polyline functions (PF)
U. Lipowezky, Selection of the Optimal Prototype Subset for 1-nn Classification. Pattern Recognition Letters 19:10 (1998) 907–918, doi: 10.1016/S0167-8655(98)00075-0
- Polyline functions (PF)
- 2000
- Modified Edited Nearest Neighbor (MENN)
K. Hattori, M. Takahashi, A New Edited K-Nearest Neighbor Rule in the Pattern Classification Problem. Pattern Recognition 33:3 (2000) 521–528, doi: 10.1016/S0031-3203(99)00068-0
- Decremental Reduction Optimization Procedure 1 (DROP1)
- Decremental Reduction Optimization Procedure 2 (DROP2)
- Decremental Reduction Optimization Procedure 3 (DROP3)
- Decremental Reduction Optimization Procedure 4 (DROP4)
- Decremental Reduction Optimization Procedure 5 (DROP5)
- Decremental Enconding Length (DEL)
D. R. Wilson, T. R. Martinez, Reduction Techniques for Instance-Based Learning Algorithms. Machine Learning 38:3 (2000) 257–286, doi: 10.1023/A:1007626913721
- Prototype Selection using Relative Certainty Gain (PSRCG)
M. Sebban, R. Nock, Instance Pruning as an Information Preserving Problem. Proceedings of the Seventeenth International Conference on Machine Learning (2000) 855–862 .
M. Sebban, R. Nock, E. Brodley, A. Danyluk, Stopping Criterion for Boosting-Based Data Reduction Techniques: From Binary to Multiclass Problems. Journal of Machine Learning Research, 3 (2002) 863–885.
- Modified Edited Nearest Neighbor (MENN)
- 2001
- Estimation of Distribution Algorithm (EDA)
B. Sierra, E. Lazkano, I. Inza, M. Merino, P. Larrañaga, J. Quiroga, Prototype Selection and Feature Subset Selection by Estimation of Distribution Algorithms. A Case Study in the Survival of Cirrhotic Patients Treated with TIPS. Proceedings of the 8th Conference on AI in Medicine in Europe, Lecture Notes in Computer Science 2101 (2001) 20–29.
- Tabu Search (CerverónTS)
V. Cerverón, F. J. Ferri, Another Move Toward the Minimum Consistent Subset: A Tabu Search Approach to the Condensed Nearest Neighbor Rule. IEEE Transactions on Systems, Man, and Cybernetics--Part B:Cybernetics 31:3 (2001) 408–413 ,doi: 10.1109/3477.931531
- Estimation of Distribution Algorithm (EDA)
- 2002
- Iterative Case Filtering (ICF)
H. Brighton, C. Mellish, Advances in Instance Selection for Instance-Based Learning Algorithms. Data Mining and Knowledge Discovery 6:2 (2002) 153–172, doi: 10.1023/A:1014043630878
- Modified Condensed Nearest Neighbor (MCNN)
V. S. Devi, M. N. Murty, An Incremental Prototype Set Building Technique. Pattern Recognition 35:2 (2002) 505–513, doi: 10.1016/S0031-3203(00)00184-9
- Intelligent Genetic Algorithm (IGA)
S.-Y. Ho, C.-C. Liu, S. Liu, Design of an Optimal Nearest Neighbor Classifier Using an Intelligent Genetic Algorithm. Pattern Recognition Letters 23:13 (2002) 1495–1503, doi: 10.1016/S0167-8655(02)00109-5
- Tabu Search (ZhangTS)
H. Zhang, G. Sun, Optimal Reference Subset Selection for Nearest Neighbor Classification by Tabu Search. Pattern Recognition 35:7 (2002) 1481–1490, doi: 10.1016/S0031-3203(01)00137-6
- Improved KNN (IKNN)
Y. Wu, K. G. Ianakiev, V. Govindaraju, Improved K-Nearest Neighbor Classification. Pattern Recognition 35:10 (2002) 2311–2318, doi: 10.1016/S0031-3203(01)00132-7
- Iterative Case Filtering (ICF)
- 2003
- Iterative Maximal Nearest Centroid Neighbor (Iterative MaxNCN)
- Reconsistent (Reconsistent)
M. T. Lozano, J. S. Sánchez, and F. Pla, Using the Geometrical Distribution of Prototypes for Training Set Condensing. CAEPIA, Lecture Notes in Computer Science (2003) 618–627.
- C-Pruner (CPruner)
K. P. Zhao, S. G. Zhou, J. H. Guan, and A. Y. Zhou, C-Pruner: An Improved Instance Pruning Algorithm. Proceedings of the 2th International Conference on Machine Learning and Cybernetics (2003) 94–99, doi: 10.1109/ICMLC.2003.1264449
- Steady-State Genetic Algorithm (SSGA)
- Population Based Incremental Learning (PBIL)
- CHC Evolutionary Algorithm (CHC)
J. R. Cano, F. Herrera, M. Lozano, Using Evolutionary Algorithms as Instance Selection for Data Reduction in KDD: An Experimental Study. IEEE Transactions on Evolutionary Computation 7:6 (2003) 561–575, doi: 10.1109/TEVC.2003.819265
- Patterns by Ordered Projections (POP)
J. C. R. Santos, J. S. Aguilar-Ruiz, M. Toro, Finding Representative Patterns With Ordered Projections. Pattern Recognition, 36:4 (2003) 1009–1018, doi: 10.1016/S0031-3203(02)00119-X
- Nearest Centroid Neighbor Edition (NCNEdit)
J. S. Sánchez, R. Barandela, A. I. Marqués, R. Alejo, J. Badenas, Analysis of New Techniques to Obtain Quality Training Sets. Pattern Recognition Letters 24:7 (2003) 1015–1022, doi: 10.1016/S0167-8655(02)00225-8
- 2004
- Edited Normalized Radial Basis Function (ENRBF)
- Edited Normalized Radial Basis Function (ENRBF2)
N. Jankowski, M. Grochowski, Comparison of Instance Selection Algorithms. I. Algorithms Survey. ICAISC, Lecture Notes in Computer Science 3070 (2004) 598–603.
- 2005
- Edited Nearest Neighbor Estimating Class Probabilistic (ENNProb)
- Edited Nearest Neighbor Estimating Class Probabilistic and Threshold(ENNTh)
F. Vázquez, J. S. Sánchez, and F. Pla, A Stochastic Approach to Wilson’s Editing Algorithm. 2nd Iberian Conference on Pattern Recognition and Image Analysis, Lecture Notes in Computer Science 3523(2005) 35–42, doi: 10.1007/11492542_5
- Support Vector based Prototype Selection (SVBPS)
Y. Li, Z. Hu, Y. Cai, W. Zhang, Support Vector Based Prototype Selection Method for Nearest Neighbor Rules. Proceedings of the First International Conference on Advances in Natural Computation, Lecture Notes in Computer Science 3610 (2005) 528–535, doi: 10.1007/11539087_68
- Backward Sequential Edition (BSE)
J. A. Olvera-López, J. F. Martínez-Trinidad, and J. A. Carrasco-Ochoa, Edition Schemes Based on BSE. Proceedings of the 10th Iberoamerican Congress on Pattern Recognition (CIARP), Lecture Notes in Computer Science 3773 (2005) 360–367, doi: 10.1007/11578079_38
- Modified Selective Subset (MSS)
R. Barandela, F. J. Ferri, J. S. Sánchez, Decision Boundary Preserving Prototype Selection for Nearest Neighbor Classification. International Journal of Pattern Recognition and Artificial Intelligence 19:6 (2005) 787–806, doi: 10.1142/S0218001405004332
- 2006
- Generalized Condensed Nearest Neighbor (GCNN)
F. Chang, C.-C. Lin, C.-J. Lu, Adaptive Prototype Learning Algorithms: Theoretical and Experimental Studies. Journal of Machine Learning Research 7 (2006) 2125–2148 .
- Generalized Condensed Nearest Neighbor (GCNN)
- 2007
- Fast Condensed Nearest Neighbor 1(FCNN)
- Fast Condensed Nearest Neighbor 2(FCNN2)
- Fast Condensed Nearest Neighbor 3(FCNN3)
- Fast Condensed Nearest Neighbor 4(FCNN4)
F. Angiulli, Fast Nearest Neighbor Condensation for Large Data Sets Classification. IEEE Transactions on Knowledge and Data Engineering, 19:11 (2007) 1450–1464, doi: 10.1109/TKDE.2007.190645
- 2008
- Noise Removing based on Minimal Consistent Set (NRMCS)
X. Z. Wang, B. Wu, Y. L. He, X. H. Pei. NRMCS : Noise Removing Based on the MCS. Proceedings of the Seventh International Conference on Machine Learning and Cybernetics (2008) 89–93, doi: 10.1109/ICMLC.2008.4620384
- Genetic Algorithm based on Mean Square Error, Clustered Crossover and Fast Smart Mutation (GA-MSE-CC-FSM)
R. Gil-Pita, X. Yao, Evolving Edited K-Nearest Neighbor Classifiers. International Journal of Neural Systems 18:6 (2008) 459–467, doi: 10.1142/S0129065708001725
- Steady-State Memetic Algorithm (SSMA)
S. García, J. R. Cano, F. Herrera, A Memetic Algorithm for Evolutionary Prototype Selection: A Scaling Up Approach. Pattern Recognition 41:8 (2008) 2693–2709, doi: 10.1016/j.patcog.2008.02.006
- Hit Miss Network C (HMNC)
- Hit Miss Network Edition (HMNE)
- Hit Miss Network Edition Iterative (HMNEI)
E. Marchiori, Hit Miss Networks With Applications to Instance Selection. Journal of Machine Learning Research 9 (2008) 997–1017.
- Noise Removing based on Minimal Consistent Set (NRMCS)
- 2009
- Template Reduction for KNN (TRKNN)
H. A. Fayed, A. F. Atiya, A Novel Template Reduction Approach for the K-Nearest Neighbor Method. IEEE Transactions on Neural Networks, 20:5 (2009) 890–896, doi: 10.1109/TNN.2009.2018547
- Template Reduction for KNN (TRKNN)
- 2010
- Prototype Selection based on Clustering (PSC)
J. A. Olvera-López, J. A. Carrasco-Ochoa, and J. F. Martínez-Trinidad, A New Fast Prototype Selection Method Based on Clustering. Pattern Analysis and Applications 13:2 (2010) 131–141, doi: 10.1007/s10462-010-9165-y
- Class Conditional Instance Selection (CCIS)
E. Marchiori, Class Conditional Nearest Neighbor for Large Margin Instance Selection. IEEE Transactions on Pattern Analysis and Machine Intelligence 32 (2010) 364–370, doi: 10.1109/TPAMI.2009.164
- Cooperative Coevolutionary Instance Selection (CoCoIS)
N. García-Pedrajas, J. A. Romero Del Castillo, and D. Ortiz-Boyer, A Cooperative Coevolutionary Algorithm for Instance Selection for Instance-Based Learning. Machine Learning 78:3 (2010) 381–420, doi: 10.1007/s10044-008-0106-1
- Prototype Selection based on Clustering (PSC)
Experimental Analyses
Comparative analyses regarding the most popular Prototype Selection methods are provided in this section. They have been taken from the SCI2 survey on Prototype Selection (S. García, J. Derrac, J.R. Cano and F. Herrera, Prototype Selection for Nearest Neighbor Classification: Taxonomy and Empirical Study. IEEE Transactions on Pattern Analysis and Machine Intelligence 34:3 (2012) 417-435 doi: 10.1109/TPAMI.2011.142). The data sets, parameters, and the rest of features of the experimental study are described at the survey complementary web page.
Result sheets are categorized regarding the method's main place in the taxonomy: Condensation, Edition and Hybrid methods, including results for 1-NN and 3-NN (that is, considering one and three neighbors in the decision rule). For each category, average results in accuracy, kappa, reduction rate, running time and other composite measures are provided:
- 1-NN
- Condensation methods:
- Small data sets


- Medium data sets
- Small data sets
- Edition methods:
- Small data sets
- Medium data sets
- Small data sets
- Hybrid methods:
- Small data sets
- Medium data sets
- Small data sets
- All methods:
- Small data sets
- Medium data sets
- Small data sets
- Condensation methods:
- 3-NN
- Condensation methods:
- Small data sets
- Medium data sets
- Small data sets
- Edition methods:
- Small data sets
- Medium data sets
- Small data sets
- Hybrid methods:
- Small data sets
- Medium data sets
- Small data sets
- All methods:
- Small data sets
- Medium data sets
- Small data sets
- Condensation methods:
All results (zipped): ![]()
SCI2S Approaches on Prototype Selection
Below we provide an outline of the SCI2S published proposals on Prototype Selection.
J.R. Cano, F. Herrera, M. Lozano. Using Evolutionary Algorithms as Instance Selection for Data Reduction in KDD: An Experimental Study. IEEE Transactions on Evolutionary Computation, 7:6 (2003) 561-575 doi: 10.1109/TEVC.2003.819265 ![]()
Abstract: Evolutionary algorithms are adaptive methods based on natural evolution that may be used for search and optimization. As data reduction in knowledge discovery in databases (KDDs) can be viewed as a search problem, it could be solved using evolutionary algorithms (EAs).
In this paper, we have carried out an empirical study of the performance of four representative EA models in which we have taken into account two different instance selection perspectives, the prototype selection and the training set selection for data reduction in KDD. This paper includes a comparison between these algorithms and other nonevolutionary instance selection algorithms. The results show that the evolutionary instance selection algorithms consistently outperform the nonevolutionary ones, the main advantages being: better instance reduction rates, higher classification accuracy, and models that are easier to interpret.
S. García, J.R. Cano, F. Herrera. A Memetic Algorithm for Evolutionary Prototype Selection: A Scaling Up Approach. Pattern Recognition, 41:8 (2008) 2693-2709 doi: 10.1016/j.patcog.2008.02.006 ![]()
Abstract: Prototype selection problem consists of reducing the size of databases by removing samples that are considered noisy or not influential on nearest neighbour classification tasks. Evolutionary algorithms have been used recently for prototype selection showing good results. However, due to the complexity of this problem when the size of the databases increases, the behaviour of evolutionary algorithms could deteriorate considerably because of a lack of convergence. This additional problem is known as the scaling up problem.
Memetic algorithms are approaches for heuristic searches in optimization problems that combine a population-based algorithm with a local search. In this paper, we propose a model of memetic algorithm that incorporates an ad hoc local search specifically designed for optimizing the properties of prototype selection problem with the aim of tackling the scaling up problem. In order to check its performance, we have carried out an empirical study including a comparison between our proposal and previous evolutionary and non-evolutionary approaches studied in the literature.
The results have been contrasted with the use of non-parametric statistical procedures and show that our approach outperforms previously studied methods, especially when the database scales up.
S. García, J. Derrac, J.R. Cano, F. Herrera. Prototype Selection for Nearest Neighbor Classification: Taxonomy and Empirical Study. IEEE Transactions on Pattern Analysis and Machine Intelligence 34:3 (2012) 417-435. doi: 10.1109/TPAMI.2011.142 ![]() COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes.
COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes.
Abstract: The nearest neighbor classifier is one of the most used and well known techniques for performing recognition tasks. It has also demonstrated itself to be one of the most useful algorithms in data mining in spite of its simplicity. However, the nearest neighbor classifier suffers from several drawbacks such as high storage requirements, low efficiency in classification response and low noise tolerance. These weaknesses have been the subject of study for many researchers and many solutions have been proposed. Among them, one of the most promising solutions consists of reducing the data used for establishing a classification rule (training data), by means of selecting relevant prototypes. Many prototype selection methods exist in the literature and the research in this area is still advancing. Different properties could be observed in the definition of them but no formal categorization has been established yet. This paper provides a survey of the prototype selection methods proposed in the literature from a theoretical and empirical point of view. Considering a theoretical point of view, we propose a taxonomy based on the main characteristics presented in prototype selection and we analyze their advantages and drawbacks. Empirically, we conduct an experimental study involving different sizes of data sets for measuring their performance in terms of accuracy, reduction capabilities and run-time. The results obtained by all the methods studied have been verified by nonparametric statistical tests. Several remarks, guidelines and recommendations are made for the use of prototype selection for nearest neighbor classification.
Prototype Generation
Background
Prototype Generation (I. Triguero, J. Derrac, S. García, F. Herrera, A Taxonomy and Experimental Study on Prototype Generation for Nearest Neighbor Classification. IEEE Transactions on Systems, Man, and Cybernetics--Part C: Applications and Reviews (In press) doi: 10.1109/TSMCC.2010.2103939) is an important technique in data reduction. It has been widely applied to instance-based classifiers and can be defined as the application of instance construction algorithms over a data set to improve the classification accuracy of a nearest neighbor classifier.
Prototype Generation builds new artificial examples from the training set, a formal specification of the problem is the following: Let $X_p$ be an instance where $X_p = (X_{p1}, X_{p2}, ... , X_{pm}, X_{pc})$, with $X_p$ belonging to a class c given by $X_{pc}$, and a m-dimensional space in which $X_{pi}$ is the value of the i-th feature of the p-th sample. Then, let us assume that there is a training set TR which consists of N instances, and a test set TS composed of T instances Xt with t\omega unknown. The purpose of Prototype Generation is to obtain a prototype generate set TG, which consists of r, r < N, prototypes, which are either selected or generated from the examples of TR. The prototypes of the generated set are determined to represent efficiently the distributions of the classes and to discriminate well when used to classify the training objects. Their cardinality should be sufficiently small to reduce both the storage and evaluation time spent by a KNN classifier.
Prototype Generation methods follow different heuristic operations to generate a set of examples which adjusts the decision boundaries between classes. The first approach we can find in the literature, called PNN ( C.-L. Chang, Finding prototypes for nearest neighbor classifiers. IEEE Transactions on Computers 23:11 (1974) 1179–1184.) belongs to the family of methods that carry out merging of prototypes of the same class in successive iterations, generating centroids. One of the most important families of methods are those based on Learning Vector Quantization ( T. Kohonen, The self organizing map. Proceedings of the IEEE 78:9 (1990) 1464–1480.) which tries to adjust the positioning of the prototypes. Other well-known methods are those based on a divide-and-conquer scheme, by separating the m-dimensional into two or more subspaces with the purpose of simplifying the problem in each step ( C. H. Chen and A. Jozwik, A sample set condensation algorithm for the class sensitive artificial neural network. Pattern Recognition Letters 17:8 (1996) 819–823.).
Similarly to Prototype Selection, evolutionary algorithms have been successfully used in Prototype Generation since it can be expressed as a continuous space search problem. These algorithms are based on the positioning adjustment of prototypes, which is a suitable methodology to optimize their location. It has become a outstanding methodology for the resolution of the Prototype Generation problem.
Taxonomy
This section presents different properties of Prototype Generation methods which define their taxonomy. The most important aspects to categorize the Prototype Generation algorithms are the following:
- Type of Reduction: It refers to the directions in which the search of a reduced set TG of prototypes, to represent the training set, can proceed: Incremental, decremental, fixed or mixed.
- Resulting generation set: This factor refers to the resulting set generated by the technique, that is, whether the final set will retain border, central or both types of points.
- Generation mechanisms: This factor describes the different mechanisms adopted in the literature to build the final TG set.
- Evaluation of Search: The last criteria relates to the way in which each step of the search is evaluated. KNN itself is an appropriate heuristic to guide the search of a Prototype Generation method. The decisions made by the heuristic must have an evaluation measure that allows the comparison of different alternatives. The evaluation of search criterion depends on the use or not of KNN in such an evaluation, and it can be divided into three categories: Filter, Semi-Wrapper and Wrapper.
Figure 3 shows a map of the taxonomy, categorizing all the Prototype Generation methods described in this website. Later, they will be described and referenced.
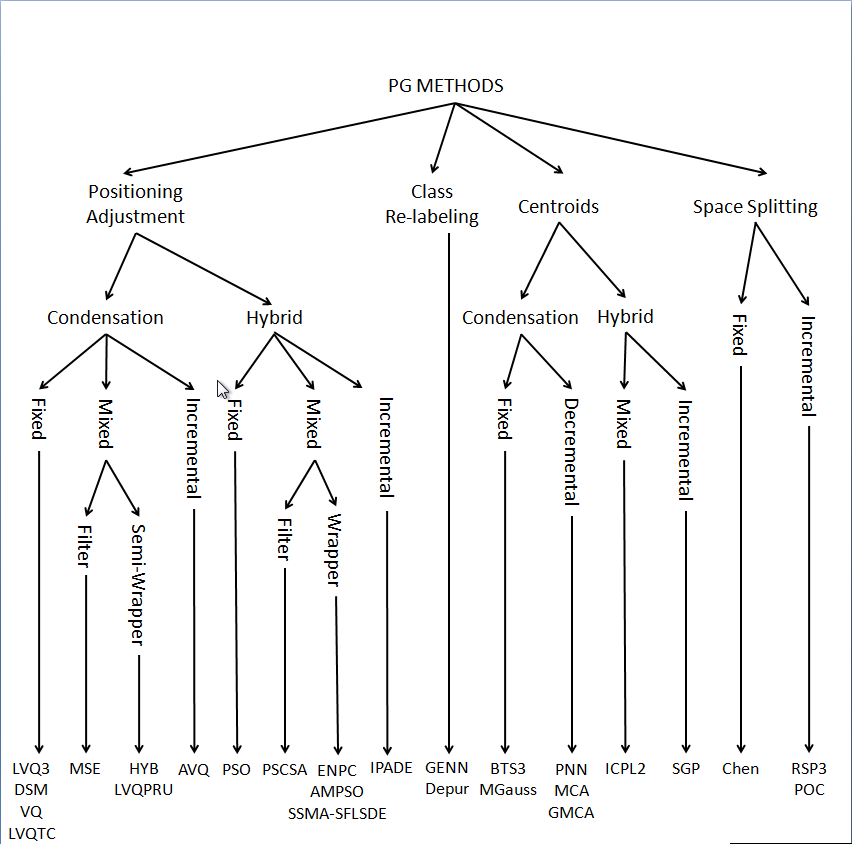
Figure 3. Prototype Generation Taxonomy
The features that define each category are shown as follows:
- Type of Reduction:
- Incremental: An incremental reduction starts with an empty reduced set TG or with only some representative prototypes from each class. Next, a succession of additions of new prototypes or modifications of previous prototypes occurs. One important advantage of this kind of reduction is that these techniques can be faster and need less storage during the learning phase than non-incremental algorithms. Furthermore, this type of reduction allows the technique to adequately establish the number of prototypes required for each data set. Nevertheless, this could obtain adverse results due to the requirement of a high number of prototypes to adjust TR producing overfitting.
- Decremental: The decremental reduction begins with TG = TR, and then the algorithm starts reducing TG or modifying the prototypes in TG. It can be accomplished by following different procedures, such as merging, moving or removing prototypes and re-labeling classes. One advantage observed in decremental schemes, is that all training examples are available for examination to make a decision. On the other hand, a shortcoming of these kind of methods is that they usually present a high computational cost.
- Fixed: It is common to use a fixed reduction in Prototype Generation. These methods establish the final number of prototypes for TG using a user previously defined parameter related to the percentage of retention of TR. This is the main drawback of this approach, apart from that is very dependent on each data set tackled. However, these techniques only focus on increasing the classification accuracy.
- Mixed: A mixed reduction begins with a pre-selected subset TG, obtained either by random selection with fixed reduction or by the run of a Prototype Selection method, and next, additions, modifications and removals of prototypes are done in TG. This type of reduction combines the advantages of the previously seen, allowing several rectifications to solve the problem of fixed reduction. However, these techniques are prone to overfit the data and they usually have high computational cost.
- Resulting generation set
- Condensation: This set includes the techniques which return a reduced set of prototypes which are closer to the decision boundaries, also called border points. The reasoning behind retaining border points is that internal points do not affect the decision boundaries as much as border points, and thus can be removed with relatively little effect on classification. The idea behind these methods is to preserve the accuracy over the training set, but the generalization accuracy over the test set can be negatively affected. Nevertheless, the reduction capability of condensation methods is normally high due to the fact that border points are less than internal points in most of the data.
- Edition: These schemes instead seek to remove or modify border points. They act over points that are noisy or do not agree with their nearest neighbors leaving smoother decision boundaries behind. However, such algorithms do not remove internal points that do not necessarily contribute to the decision boundaries. The effect obtained is related to the improvement of generalization accuracy in test data, although the reduction rate obtained is lower.
- Hybrid: Hybrid methods try to find the smallest set TG which maintains or even increases the generalization accuracy in test data. To achieve this, it allows modifications of internal and border points based on some specific criteria followed by the algorithm. The KNN classifier is highly adaptable to these methods, obtaining great improvements even with a very small reduced set of prototypes.
- Generation mechanisms
- Class re-labeling: This generation mechanism consists of changing the class labels of samples from TR which could be suspicious of being errors and belonging to other different classes. Its purpose is to cope with all types of imperfections in the training set (mislabeled, noisy and atypical cases). The effect obtained is closely related to the improvement in generalization accuracy of the test data, although the reduction rate is kept fixed.
- Centroid based: These techniques are based on generating artificial prototypes by merging a set of similar examples. The merging process is usually made from the computation of averaged attribute values over a selected set, yielding the so-called centroids. The identification and selection of the set of examples are the main concerns of the algorithms that belong to this category. These methods can obtain a high reduction rate but they are also related to accuracy rate losses.
- Space Splitting: This set includes the techniques based on different heuristics for partitioning the feature space, along with several mechanisms to define new prototypes. The idea consists of dividing TR into some regions which will be replaced with representative examples establishing the decision boundaries associated with the original TR. This mechanism works on a space level, due to the fact that the partitions are found in order to discriminate, as well as possible, a set of examples from others, whereas centroid based approaches work on the data level, mainly focusing on the optimal selection of only a set of examples to be treated. The reduction capabilities of these techniques usually depend on the number of regions that are needed to represent TR.
- Positioning Adjustment: The methods that belong to this family aim to correct the position of a subset of prototypes from the initial set by using an optimization procedure. New positions of prototype can be obtained using the movement idea in the m-dimensional space, adding or subtracting some quantities to the attribute values of the prototypes. This mechanism is usually associated to a fixed or mixed type of reduction.
- Evaluation of Search
- Filter: We refer to filters techniques when they do not use the KNN rule during the evaluation phase. Different heuristics are used to obtain the reduced set. They can be faster than KNN but the performance in terms of accuracy obtained could be worse.
- Semi-Wrapper: KNN is used for partial data to determine the criteria of making a certain decision. Thus, KNN performance can be measured over localized data, which will contain most of prototypes that will be influenced in making a decision. It is an intermediate approach, where a trade-off between efficiency and accuracy is expected.
- Wrapper: In this case, the KNN rule fully guides the search by using the complete training set with the leave-one-out validation scheme. The conjunction in the use of the two mentioned factors allows us to get a great estimator of generalization accuracy, thus obtaining better accuracy over test data. However, each decision involves a complete computation of the KNN rule over the training set and the evaluation phase can be computationally expensive.
Prototype Generation Methods
The Prototype Generation field has provided a considerable number of methods over the last forty years. Figure 4 depicts the evolution of the area, showing the year of publication of each method. Since the methods are gathered regarding their place in the taxonomy, this map also allows to observe the differences in the growth of each of the sub-areas.
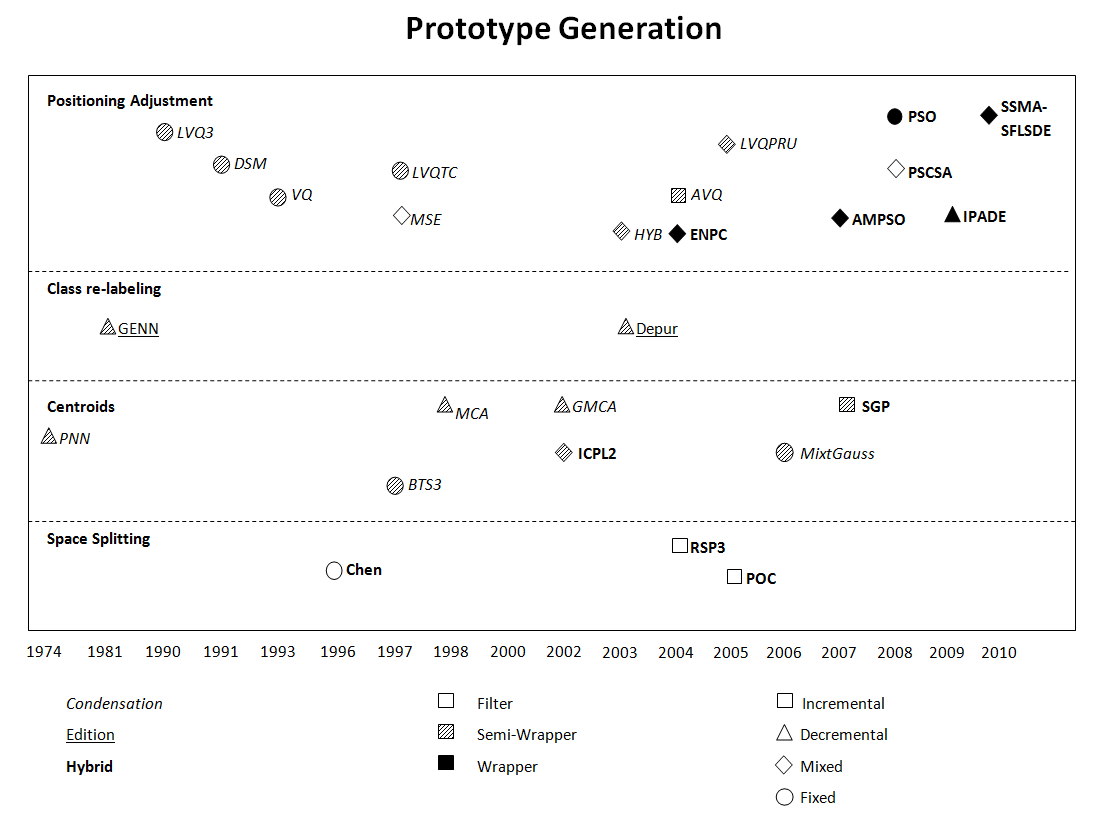
Figure 4. Evolution map of the Prototype Generation field
Each dot considered in the map represent a significant contribution in the area. More details about them can be found in the SCI2S technical report about Prototype Selection methods:
I. Triguero, J. Derrac, S. García, and F.Herrera, Prototype Generation for Nearest Neighbor Classification: Survey of Methods. ![]()
References of the methods (by year of publishing)
- 1974
- Prototype Nearest Neighbor (PNN)
C.-L. Chang, Finding prototypes for nearest neighbor classifiers. IEEE Transactions on Computers 23:11 (1974) 1179–1184, doi: 10.1109/T-C.1974.223827
- Prototype Nearest Neighbor (PNN)
- 1981
- Generalized Editing using Nearest Neighbor (GENN)
J. Koplowitz and T. Brown, On the relation of performance to editing in nearest neighbor rules. Pattern Recognition 13 (1981) 251–255, doi: 10.1016/0031-3203(81)90102-3
- Generalized Editing using Nearest Neighbor (GENN)
- 1990
- Learning Vector Quantization 1 (LVQ1)
- Learning Vector Quantization 2 (LVQ2)
- Learning Vector Quantization 2.1 (LVQ2.1)
- Learning Vector Quantization 3 (LVQ3)
T. Kohonen, The self organizing map. Proceedings of the IEEE 78:9 (1990) 1464–1480.
- 1991
- Decision Surface Mapping (DSM)
S. Geva and J. Sitte, Adaptive nearest neighbor pattern classification. IEEE Transaction On Neural Networks 2:2 (1991) 318–322, doi: 10.1109/72.80344
- Decision Surface Mapping (DSM)
- 1993
- Vector Quantization (VQ)
Q. Xie, C. A. Laszlo, and R. K. Ward, Vector quantization technique for nonparametric classifier design. IEEE Transactions On Pattern Analysis and Machine Intelligence 15:12 (1993) 1326–1330, doi: 10.1109/34.250849
- Vector Quantization (VQ)
- 1996
- Chen Algorithm (Chen)
C. H. Chen and A. Jozwik, A sample set condensation algorithm for the class sensitive artificial neural network. Pattern Recognition Letters 17:8 (1996) 819–823, doi: 10.1016/0167-8655(96)00041-4
- Chen Algorithm (Chen)
- 1997
- Bootstrap Technique for Nearest Neighbor (BTS3)
Y. Hamamoto, S. Uchimura, and S. Tomita, A bootstrap technique for nearest neighbor classifier design. IEEE Transactions on Pattern Analysis and Machine Intelligence 19:1 (1997) 73–79, doi: 10.1109/34.566814
- Learning Vector Quantization with Training Counter (LVQTC)
R. Odorico, Learning vector quantization with training count (LVQTC). Neural Networks 10:6 (1997) 1083–1088, doi: 10.1016/S0893-6080(97)00012-9
- MSE (MSE)
C. Decaestecker, Finding prototypes for nearest neghbour classification by means of gradient descent and deterministic annealing. Pattern Recognition 30:2 (1997) 281–288, doi: 10.1016/S0031-3203(96)00072-6
- Bootstrap Technique for Nearest Neighbor (BTS3)
- 1998
- Modified Chang’s Algorithm (MCA)
T. Bezdek, J.C .and Reichherzer, G. Lim, and Y. Attikiouzel, Multiple prototype classifier design. IEEE Transactions on Systems, Man and Cybernetics C 28:1, (1998) 6779-6786, doi: 10.1109/5326.661091
- Modified Chang’s Algorithm (MCA)
- 2002
- Generalized Modified Chang’s Algorithm (GMCA)
R. Mollineda, F. Ferri, E. Vidal, A merge-based condensing strategy for multiple prototype classifiers. IEEE Transactions on Systems, Man and Cybernetics B 32:5 (2002) 662–668, doi: 10.1109/TSMCB.2002.1033185
- Integrated Concept Prototype Learner (ICPL)
- Integrated Concept Prototype Learner 2 (ICPL2)
- Integrated Concept Prototype Learner 3 (ICPL3)
- Integrated Concept Prototype Learner 4 (ICPL4)
W. Lam, C. K. Keung, and D. Liu, Discovering useful concept prototypes for classification based on filtering and abstraction. IEEE Transactions on Pattern Analysis and Machine Intelligence 14:8 (2002) 1075-1090, doi: 10.1109/TPAMI.2002.1023804
- Generalized Modified Chang’s Algorithm (GMCA)
- 2003
- Depuration Algorithm (Depur)
J. S. Sánchez, R. Barandela, A. I. Marqués, R. Alejo, and J. Badenas, Analysis of new techniques to obtain quality training sets. Pattern Recognition Letters 24:7 (2003) 1015-1022, doi: 10.1016/S0167-8655(02)00225-8
- Hybrid LVQ3 algorithm (HYB)
S. W. Kim and J. Oomenn, Enhancing prototype reduction schemes with lvq3-type algorithms. Pattern Recognition 36 (2003) 1083–1093, doi: 10.1016/S0031-3203(02)00115-2
- Depuration Algorithm (Depur)
- 2004
- Reduction by space partitioning 1 (RSP1)
- Reduction by space partitioning 2 (RSP2)
- Reduction by space partitioning 3 (RSP3)
J. S. Sánchez, High training set size reduction by space partitioning and prototype abstraction. Pattern Recognition 37:7 (2004) 1561-1564, doi: 10.1016/j.patcog.2003.12.012
- Evolutionary Nearest Prototype Classifier (ENPC)
F. Fernández and P. Isasi, Evolutionary design of nearest prototype classifiers. Journal of Heuristics 10:4 (2004) 431–454, doi: 10.1023/B:HEUR.0000034715.70386.5b
- Adaptive Vector Quantization (AVQ)
C.-W. Yen, C.-N. Young, and M. L. Nagurka, A vector quantization method for nearest neighbor classifier design. Pattern Recognition Letters 25:6 (2004) 725–731, doi: 10.1016/j.patrec.2004.01.012
- 2005
- Learning Vector Quantization with Pruning (LVQPRU)
J. Li, M. T. Manry, C. Yu, and D. R. Wilson, Prototype classifier design with pruning. International Journal on Artificial Intelligence Tools 14:1-2 (2005) 261–280, doi: 10.1142/S0218213005002090
- Pairwise Opposite Class Nearest Neighbor (POC-NN)
T. Raicharoen and C. Lursinsap, A divide-and-conquer approach to the pairwise opposite class-nearest neighbor (POC-NN) algorithm. Pattern Recognition Letters 26 (2005) 1554-1567, doi: 10.1016/j.patrec.2005.01.003
- Learning Vector Quantization with Pruning (LVQPRU)
- 2006
- Adaptive Condensing Algorithm Based on Mixtures of Gaussians (MGauss)
M. Lozano, J. M. Sotoca, J. S. Sánchez, F. Pla, E. Pekalska, and R. P. W. Duin, Experimental study on prototype optimisation algorithms for prototype-based classification in vector spaces. Pattern Recognition 39:10 (2006) 1827–1838, doi: 10.1016/j.patcog.2006.04.005
- Adaptive Condensing Algorithm Based on Mixtures of Gaussians (MGauss)
- 2007
- Self-generating Prototypes (SGP)
H. A. Fayed, S. R. Hashem, and A. F. Atiya, Self-generating prototypes for pattern classification. Pattern Recognition 40:5 (2007) 1498-1509, doi: 10.1016/j.patcog.2006.10.018
- Adaptive Michigan Particle Swarm Optimization (AMPSO)
A. Cervantes, I. Galván, P. Isasi, An Adaptive Michigan Approach PSO for Nearest Prototype Classification. 2nd International Work-Conference on the Interplay Between Natural and Artificial Computation (IWINAC07). LNCS 4528, Springer 2007, La Manga del Mar Menor (Spain, 2007) 287-296, doi: 10.1007/978-3-540-73055-2_31
A. Cervantes, I. M. Galván, and P. Isasi, AMPSO: A new particle swarm method for nearest neighborhood classification. IEEE Transactions on Systems, Man, and Cybernetics - Part B: Cybernetics 39:5 (2009) 1082-1091, doi: 10.1109/TSMCB.2008.2011816
- Self-generating Prototypes (SGP)
- 2008
- Prototype Selection Clonal Selection Algorithm (PSCSA)
U. Garain, Prototype reduction using an artificial immune model. Pattern Analysis and Applications 11:3-4 (2008) 353-363, doi: 10.1007/s10044-008-0106-1
- Particle Swarm Optimization (PSO)
L. Nanni and A. Lumini, Particle swarm optimization for prototype reduction. Neurocomputing, 72:4-6 (2008) 1092–1097, doi: 10.1016/j.neucom.2008.03.008
- Prototype Selection Clonal Selection Algorithm (PSCSA)
- 2009
- Iterative Prototype Adjustment based on Differential Evolution (IPADE)
I. Triguero, S. García, F. Herrera. IPADE: Iterative Prototype Adjustment for Nearest Neighbor Classification. IEEE Transactions on Neural Networks 21:12 (2010) 1984-1990, doi: 10.1109/TNN.2010.2087415
- Iterative Prototype Adjustment based on Differential Evolution (IPADE)
- 2010
- Differential Evolution (DE)
- Self-Adaptive Differential Evolution (SADE)
- Scale Factor Local Search in Differential Evolution (SFLSDE)
- Adaptive Differential Evolution with Optional External Archive (JADE)
- Differential Evolution using a Neighborhood-Based Mutation Operator (DEGL)
- Hybrid Iterative Case Filtering + Learning Vector Quantization 3 (ICF-LVQ3)
- Hybrid Iterative Case Filtering + Particle Swarm Optimization (ICF-PSO)
- Hybrid Iterative Case Filtering + Scale Factor Local Search in Differential Evolution (ICF-SFLSDE)
- Hybrid Decremental Reduction Optimization Procedure 3 + Learning Vector Quantization 3 (DROP3-LVQ3)
- Hybrid Decremental Reduction Optimization Procedure 3 + Particle Swarm Optimization (DROP3-PSO)
- Hybrid Decremental Reduction Optimization Procedure 3 + Scale Factor Local Search in Differential Evolution (DROP3-SFLSDE)
- Hybrid Steady-State Memetic Algorithm for Instance Selection + Learning Vector Quantization 3 (SSMA-LVQ3)
- Hybrid Steady-State Memetic Algorithm for Instance Selection + Particle Swarm Optimization (SSMA-PSO)
- Hybrid Steady-State Memetic Algorithm for Instance Selection + Scale Factor Local Search in Differential Evolution (SSMA-SFLSDE)
I. Triguero, S. García, F. Herrera. Differential evolution for optimizing the positioning of prototypes in nearest neighbor classification. Pattern Recognition 44:4 (2011) 901-916, doi: 10.1016/j.patcog.2010.10.020
Experimental Analyses
In this section, the most important Prototype Generation methods are analyzed. The comparative analyses have been mostly taken from the the SCI2 survey on Prototype Generation (I. Triguero, J. Derrac, S. García, F. Herrera, A Taxonomy and Experimental Study on Prototype Generation for Nearest Neighbor Classification. IEEE Transactions on Systems, Man, and Cybernetics--Part C: Applications and Reviews (In press) doi: 10.1109/TSMCC.2010.2103939) with the addition of two more recent techniques:
- IPADE:
I. Triguero, S. García, F. Herrera. IPADE: Iterative Prototype Adjustment for Nearest Neighbor Classification. IEEE Transactions on Neural Networks 21:12 (2010) 1984-1990.
COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes.
- SSMA-SFLSDE:
I. Triguero, S. García, F. Herrera. Differential evolution for optimizing the positioning of prototypes in nearest neighbor classification. Pattern Recognition 44:4 (2011) 901-916.
The data sets, parameters, and the rest of features of the experimental study are described at the survey complementary web page. Result sheets are categorized regarding the method's main place in the taxonomy: Positioning Adjustment, Class Re-labeling, Centroids based and Space Splitting methods. For each category, average results in accuracy, kappa and reduction rate are provided:
- Positioning Adjustment methods:
- Small data sets
- Medium data sets
- Small data sets
- Class Re-labeling methods:
- Small data sets
- Medium data sets
- Small data sets
- Centroid-based methods:
- Small data sets
- Medium data sets
- Small data sets
- Space Splitting methods:
- Small data sets
- Medium data sets
- Small data sets
- All methods:
- Small data sets
- Medium data sets
- Small data sets
All results (zipped): ![]()
SCI2S Approaches on Prototype Generation
Below we provide an outline of the SCI2S published proposals on Prototype Generation.
Below we provide an outline of the SCI2S published proposals on Prototype Generation.
I. Triguero, S. García and F.Herrera, IPADE: Iterative Prototype Adjustment for Nearest Neighbor Classification. IEEE Transactions on Neural Networks 21:12 (2010) 1984-1990. COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes, doi: 10.1109/TNN.2010.2087415 ![]()
Abstract: Nearest prototype methods are a successful trend of many pattern classification tasks. However, they present several shortcomings such as time response, noise sensitivity, and storage requirements. Data reduction techniques are suitable to alleviate these drawbacks. Prototype generation is an appropriate process for data reduction, which allows the fitting of a dataset for nearest neighbor (NN) classification. This brief presents a methodology to learn iteratively the positioning of prototypes using real parameter optimization procedures. Concretely, we propose an iterative prototype adjustment technique based on differential evolution. The results obtained are contrasted with nonparametric statistical tests and show that our proposal consistently outperforms previously proposed methods, thus becoming a suitable tool in the task of enhancing the performance of the NN classifier.
I. Triguero, S. García and F.Herrera, Enhancing IPADE Algorithm with a Different Individual Codification. 6th International Conference on Hybrid Artificial Intelligence Systems (HAIS2011). LNAI 6679, Wroclaw (Poland, 2011) 262-270 ![]()
Abstract: Nearest neighbor is one of the most used techniques for performing classification tasks. However, its simplest version has several drawbacks, such as low efficiency, storage requirements and sensitivity to noise. Prototype generation is an appropriate process to alleviate these drawbacks that allows the fitting of a data set for nearest neighbor classification. In this work, we present an extension of our previous proposal called IPADE, a methodology to learn iteratively the positioning of prototypes using a differential evolution algorithm. In this extension, which we have called IPADECS, a complete solution is codified in each individual. The results are contrasted with non-parametrical statistical tests and show that our proposal outperforms previously proposed methods.
I. Triguero, S. García and F.Herrera , Differential evolution for optimizing the positioning of prototypes in nearest neighbor classification. Pattern Recognition 44:4 (2011) 901-916, doi: 10.1016/j.patcog.2010.10.020 ![]()
Abstract: Nearest neighbor classification is one of the most used and well known methods in data mining. Its simplest version has several drawbacks, such as low efficiency, high storage requirements and sensitivity to noise. Data reduction techniques have been used to alleviate these shortcomings. Among them, prototype selection and generation techniques have been shown to be very effective. Positioning adjustment of prototypes is a successful trend within the prototype generation methodology.
Evolutionary algorithms are adaptive methods based on natural evolution that may be used for searching and optimization. Positioning adjustment of prototypes can be viewed as an optimization problem, thus it can be solved using evolutionary algorithms. This paper proposes a differential evolution based approach for optimizing the positioning of prototypes. Specifically, we provide a complete study of the performance of four recent advances in differential evolution. Furthermore, we show the good synergy obtained by the combination of a prototype selection stage with an optimization of the positioning of prototypes previous to nearest neighbor classification. The results are contrasted with non-parametrical statistical tests and show that our proposals outperform previously proposed methods
I. Triguero, J. Derrac, S. García and F.Herrera, A Taxonomy and Experimental Study on Prototype Generation for Nearest Neighbor Classification. IEEE Transactions on Systems, Man, and Cybernetics--Part C: Applications and Reviews 42 (1) (2012) 86-100, doi: 10.1109/TSMCC.2010.2103939 ![]()
COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes.
Abstract: The nearest neighbor rule is one of the most successfully used techniques for resolving classification and pattern recognition tasks. Despite its high classification accuracy, this rule suffers from several shortcomings in time response, noise sensitivity and high storage requirements. These weaknesses have been tackled from many different approaches, among them, a good and well-known solution that we can find in the literature consists of reducing the data used for the classification rule (training data). Prototype reduction techniques can be divided into two different approaches, known as prototype selection and prototype generation or abstraction. The former process consists of choosing a subset of the original training data, whereas prototype generation builds new artificial prototypes to increase the accuracy of the nearest neighbor classification. In this paper we provide a survey of prototype generation methods specifically designed for the nearest neighbor rule. From a theoretical point of view, we propose a taxonomy based on the main characteristics presented in them. Furthermore, from an empirical point of view, we conduct a wide experimental study which involves small and large data sets for measuring their performance in terms of accuracy and reduction capabilities. The results are contrasted through non-parametrical statistical tests. Several remarks are made to understand which prototype generation models are appropriate for application to different data sets.
Prototype Reduction Outlook
The field of Prototype Reduction has experienced a flourishing growth in the last decades. Many interesting works have been developed under the Prototype Selection and Generation areas; not only new methods, but many survey papers and relating approaches for enhancing the quality of the KNN classifiers.
In this section, we review the most representative works in Prototype Reduction, focusing our interest in surveys and key milestones in the development in the field. Given its importance in such development, evolutionary approaches are also highlighted. In addition, other relevant approaches are pointed out, including works in stratification, data complexity, imbalanced data, hyperrectangles, hybrid approaches and so forth.
Finally, to conclude this section we give a succinct study about the Prototype Reduction Visibility at the Web of Science (WoS), which can be useful for analyzing the current state of the field.
Key Milestones & Surveys
T. M. Cover, P. E. Hart , Nearest Neighbor Pattern Classification. IEEE Transactions on Information Theory, 13 (1967) 21-27 doi: 10.1109/TIT.1967.1053964 ![]()
Abstract: The nearest neighbor decision rule assigns to an unclassified sample point the classification of the nearest of a set of previously classified points. This rule is independent of the underlying joint distribution on the sample points and their classifications, and hence the probability of error R of such a rule must be at least as great as the Bayes probability of error R* -the minimum probability of error over all decision rules taking underlying probability structure into account. However, in a large sample analysis, we will show in the M-category case that R* < R < R*(Z - MR*/(M-I)), where these bounds are the tightest possible, for all suitably smooth underlying distributions. Thus for any number of categories, the probability of error of the nearest neighbor rule is bounded above by twice the Bayes probability of error. In this sense, it may be said that half the classification information in an infiite sample set is contained iu the nearest neighbor.
D. W. Aha, D. Kibler, M. K. Albert , Instance-Based Learning Algorithms. Machine Learning, 6 (1991) 37-66 doi: 10.1023/A:1022689900470 ![]()
Abstract: Storing and using specific instances improves the performance of several supervised learning algorithms. These include algorithms that learn decision trees, classification rules, and distributed networks. However, no investigation has analyzed algorithms that use only specific instances to solve incremental learning tasks. In this paper, we describe a framework and methodology, called instance-based learning, that generates classification predictions using only specific instances. Instance-based learning algorithms do not maintain a set of abstractions derived from specific instances. This approach extends the nearest neighbor algorithm, which has large storage requirements. We describe how storage requirements can be significantly reduced with, at most, minor sacrifices in learning rate and classification accuracy. While the storage-reducing algorithm performs well on several realworld databases, its performance degrades rapidly with the level of attribute noise in training instances. Therefore, we extended it with a significance test to distinguish noisy instances. This extended algorithm's performance degrades gracefully with increasing noise levels and compares favorably with a noise-tolerant decision tree algorithm.
D. R. Wilson, T. R. Martinez Reduction Techniques for Instance-Based Learning Algorithms. Machine Learning, 38 (2000) 257–286.doi: 10.1023/A:1007626913721 ![]()
Abstract: Instance-based learning algorithms are often faced with the problem of deciding which instances to store for use during generalization. Storing too many instances can result in large memory requirements and slow execution speed, and can cause an oversensitivity to noise. This paper has two main purposes. First, it provides a survey of existing algorithms used to reduce storage requirements in instance-based learning algorithms and other exemplar-based algorithms. Second, it proposes six additional reduction algorithms called DROP1–DROP5 and DEL (three of which were first described in Wilson & Martinez, 1997c, as RT1–RT3) that can be used to remove instances from the concept description. These algorithms and 10 algorithms from the survey are compared on 31 classification tasks. Of those algorithms that provide substantial storage reduction, the DROP algorithms have the highest average generalization accuracy in these experiments, especially in the presence of uniform class noise.
J. C. Bezdek, L.I. Kuncheva ,Nearest Prototype Classifier Designs: An Experimental Study. International Journal of Intelligent Systems, 16 (2001) 1445-1473. doi: 10.1002/int.1068 ![]()
Abstract: We compare eleven methods for finding prototypes upon which to base the nearest prototype classifier. Four methods for prototype selection are discussed: Wilson + Hart (a condensation+error-editing method), and three types of combinatorial search-random search, genetic algorithm, and tabu search. Seven methods for prototype extraction are discussed: unsupervised vector quantization, supervised learning vector quantization (with and without training counters), decision surface mapping, a fuzzy version of vector quantization, c-means clustering, and bootstrap editing. These eleven methods can be usefully divided two other ways: by whether they employ pre- or post supervision; and by whether the number of prototypes found is user-defined or "automatic". Generalization error rates of the 11 methods are estimated on two synthetic and two real data sets. Offering the usual disclaimer that these are just a limited set of experiments, we feel confident in asserting that presupervised, extraction methods offer a better chance for success to the casual user than postsupervised, selection schemes. Finally, our calculations do not suggest that methods which find the "best" number of prototypes "automatically" are superior to methods for which the user simply specifies the number of prototypes.
S. W. Kim, B. J. Oommen , A brief taxonomy and ranking of creative prototype reduction schemes. Pattern Analysis and Applications 6 (2003) 232-244 doi: 10.1007/s10044-003-0191-0 ![]()
Abstract: Various Prototype Reduction Schemes (PRS) have been reported in the literature. Based on their operating characteristics, these schemes fall into two fairly distinct categories — those which are of a creative sort, and those which are essentially selective. The norms for evaluating these methods are typically, the reduction rate and the classification accuracy. It is generally believed that the former class of methods is superior to the latter. In this paper, we report the results of executing various creative PRSs, and attempt to comparatively quantify their capabilities. The paper presents a brief taxonomy of the various reported PRS schemes. Our experimental results for three artificial data sets, and for samples involving real-life data sets, demonstrate that no single method is uniformly superior to the others for all kinds of applications. This result, though consistent with the findings of Bezdek and Kuncheva, is, in one sense, counter-intuitive, because the various researchers have presented their specific PRS with the hope that it would be superior to the previously reported methods. However, the fact is that while one method is superior in certain domains, it is inferior to another method when dealing with a data set with markedly different characteristics. The conclusion of this study is that the question of determining when one method is superior to another remains open. Indeed, it appears as if the designers of the pattern recognition system will have to choose the appropriate PRS based to the specific characteristics of the data that they are studying. The paper also suggests answers to various hypotheses that relate to the accuracies and reduction rates of families of PRS.
J. Derrac, S. García, F. Herrera. A Survey on Evolutionary Instance Selection and Generation. International Journal of Applied Metaheuristic Computing, 1:1 (2010) 60-92 doi: 10.4018/IJAMC.2010010104 ![]()
Abstract: The use of Evolutionary Algorithms to perform data reduction tasks has become an effective approach to improve the performance of data mining algorithms. Many proposals in the literature have shown that Evolutionary Algorithms obtain excellent results in their application as Instance Selection and Instance Generation procedures. The purpose of this article is to present a survey on the application of Evolutionary Algorithms to Instance Selection and Generation process. It will cover approaches applied to the enhancement of the nearest neighbor rule, as well as other approaches focused on the improvement of the models extracted by some well-known data mining algorithms. Furthermore, some proposals developed to tackle two emerging problems in data mining, Scaling Up and Imbalance Data Sets, also are reviewed.
J. Olvera-López , J. Carrasco-Ochoa, J. Martínez-Trinidad, J. Kittler , A review of instance selection methods. Artificial Intelligence Review 34:2 (2010) 133-143 doi: 10.1007/s10462-010-9165-y ![]()
Abstract: In supervised learning, a training set providing previously known information is used to classify new instances. Commonly, several instances are stored in the training set but some of them are not useful for classifying therefore it is possible to get acceptable classification rates ignoring non useful cases; this process is known as instance selection. Through instance selection the training set is reduced which allows reducing runtimes in the classification and/or training stages of classifiers. This work is focused on presenting a survey of the main instance selection methods reported in the literature
I. Triguero, J. Derrac, S. García and F.Herrera, A Taxonomy and Experimental Study on Prototype Generation for Nearest Neighbor Classification. IEEE Transactions on Systems, Man, and Cybernetics--Part C: Applications and Reviews 42 (1) (2012) 86-100, doi: 10.1109/TSMCC.2010.2103939 ![]()
COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes.
Abstract: The nearest neighbor rule is one of the most successfully used techniques for resolving classification and pattern recognition tasks. Despite its high classification accuracy, this rule suffers from several shortcomings in time response, noise sensitivity and high storage requirements. These weaknesses have been tackled from many different approaches, among them, a good and well-known solution that we can find in the literature consists of reducing the data used for the classification rule (training data). Prototype reduction techniques can be divided into two different approaches, known as prototype selection and prototype generation or abstraction. The former process consists of choosing a subset of the original training data, whereas prototype generation builds new artificial prototypes to increase the accuracy of the nearest neighbor classification. In this paper we provide a survey of prototype generation methods specifically designed for the nearest neighbor rule. From a theoretical point of view, we propose a taxonomy based on the main characteristics presented in them. Furthermore, from an empirical point of view, we conduct a wide experimental study which involves small and large data sets for measuring their performance in terms of accuracy and reduction capabilities. The results are contrasted through non-parametrical statistical tests. Several remarks are made to understand which prototype generation models are appropriate for application to different data sets.
S. García, J. Derrac, J.R. Cano, F. Herrera. Prototype Selection for Nearest Neighbor Classification: Taxonomy and Empirical Study. IEEE Transactions on Pattern Analysis and Machine Intelligence 34:3 (2012) 417-435 doi: 10.1109/TPAMI.2011.142 ![]()
COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes.
Abstract: The nearest neighbor classifier is one of the most used and well known techniques for performing recognition tasks. It has also demonstrated itself to be one of the most useful algorithms in data mining in spite of its simplicity. However, the nearest neighbor classifier suffers from several drawbacks such as high storage requirements, low efficiency in classification response and low noise tolerance. These weaknesses have been the subject of study for many researchers and many solutions have been proposed. Among them, one of the most promising solutions consists of reducing the data used for establishing a classification rule (training data), by means of selecting relevant prototypes. Many prototype selection methods exist in the literature and the research in this area is still advancing. Different properties could be observed in the definition of them but no formal categorization has been established yet. This paper provides a survey of the prototype selection methods proposed in the literature from a theoretical and empirical point of view. Considering a theoretical point of view, we propose a taxonomy based on the main characteristics presented in prototype selection and we analyze their advantages and drawbacks. Empirically, we conduct an experimental study involving different sizes of data sets for measuring their performance in terms of accuracy, reduction capabilities and run-time. The results obtained by all the methods studied have been verified by nonparametric statistical tests. Several remarks, guidelines and recommendations are made for the use of prototype selection for nearest neighbor classification.
Hybrid approaches for Prototype and Feature Reduction
L. I. Kuncheva, L. C. Jain, Nearest Neighbor Classifier: Simultaneous Editing and Feature Selection. Pattern Recognition Letters 20 (1999) 1149-1156 doi: 10.1016/S0167-8655(99)00082-3 ![]()
Abstract: Nearest neighbor classifiers demand significant computational resources (time and memory). Editing of the reference set and feature selection are two different approaches to this problem. Here we encode the two approaches within the same genetic algorithm (GA) and simultaneously select features and reference cases. Two data sets were used: the SATIMAGE data and a generated data set. The GA was found to be an expedient solution compared to editing followed by feature selection, feature selection followed by editing, and the individual results from feature selection and editing.
S.-Y. Ho, C.-C. Liu, S. Liu, Design of an Optimal Nearest Neighbor Classifier Using an Intelligent Genetic Algorithm. Pattern Recognition Letters 23:13 (2002) 1495-1503 doi: 10.1016/S0167-8655(02)00109-5 ![]()
Abstract: The goal of designing an optimal nearest neighbor classifier is to maximize the classification accuracy while minimizing the sizes of both the reference and feature sets. A novel intelligent genetic algorithm (IGA) superior to conventional GAs in solving large parameter optimization problems is used to effectively achieve this goal. It is shown empirically that the IGA-designed classifier outperforms existing GA-based and non-GA-based classifiers in terms of classification accuracy and total number of parameters of the reduced sets.
J-H. Chen, H-M. Chen, S-Y. Ho Design of Nearest Neighbor Classifiers: Multi-Objective Approach. International Journal of Approximate Reasoning 40(2005) 3-22 doi: 10.1016/j.ijar.2004.11.009 ![]()
Abstract: The goal of designing optimal nearest neighbor classifiers is to maximize classification accuracy while minimizing the sizes of both reference and feature sets. A usual way is to adaptively weight the three objectives as an objective function and then use a single-objective optimization method for achieving this goal. This paper proposes a multi-objective approach to cope with the weight tuning problem for practitioners. A novel intelligent multi-objective evolutionary algorithm IMOEA is utilized to simultaneously edit compact reference and feature sets for nearest neighbor classification. Three comparison studies are designed to evaluate performance of the proposed approach. It is shown empirically that the IMOEA-designed classifiers have high classification accuracy and small sizes of reference and feature sets. Moreover, IMOEA can provide a set of good solutions for practitioners to choose from in a single run. The simulation results indicate that the IMOEA-based approach is an expedient method to design nearest neighbor classifiers, compared with an existing single-objective approach.
F. Ros, S. Guillaume, M. Pintore, J. R. Chretien, Hybrid genetic algorithm for dual selection. Pattern Analysis and Applications 11(2008) 179-198 doi: 10.1007/s10044-007-0089-3 ![]()
Abstract: In this paper, a hybrid genetic approach is proposed to solve the problem of designing a subdatabase of the original one with the highest classification performances, the lowest number of features and the highest number of patterns. The method can simultaneously treat the double problem of editing instance patterns and selecting features as a single optimization problem, and therefore aims at providing a better level of information. The search is optimized by dividing the algorithm into selfcontrolled phases managed by a combination of pure genetic process and dedicated local approaches. Different heuristics such as an adapted chromosome structure and evolutionary memory are introduced to promote diversity and elitism in the genetic population. They particularly facilitate the resolution of real applications in the chemometric field presenting databases with large feature sizes and medium cardinalities. The study focuses on the double objective of enhancing the reliability of results while reducing the time consumed by combining genetic exploration and a local approach in such a way that excessive computational CPU costs are avoided. The usefulness of the method is demonstrated with artificial and real data and its performance is compared to other approaches.
J. Derrac, S. García, F. Herrera, Instance and Feature Selection based on Cooperative Coevolution with Nearest Neighbor Rule. Pattern Recognition 43:6 (2010) 2082-2105 doi: 10.1016/j.patcog.2009.12.012 ![]()
Abstract: Feature and instance selection are two effective data reduction processes which can be applied to classification tasks obtaining promising results. Although both processes are defined separately, it is possible to apply them simultaneously. This paper proposes an evolutionary model to perform feature and instance selection in nearest neighbor classification. It is based on cooperative coevolution, which has been applied to many computational problems with great success. The proposed approach is compared with a wide range of evolutionary feature and instance selection methods for classification. The results contrasted through non-parametric statistical tests show that our model outperforms previously proposed evolutionary approaches for performing data reduction processes in combination with the nearest neighbor rule.
J. Derrac, C. Cornelis, S. García, F. Herrera, Enhancing evolutionary instance selection algorithms by means of fuzzy rough set based feature selection. Information Sciences 186 (2012) 73–92 doi: 10.1016/j.ins.2011.09.027 ![]()
Abstract: In recent years, fuzzy rough set theory has emerged as a suitable tool for performing feature selection. Fuzzy rough feature selection enables us to analyze the discernibility of the attributes, highlighting the most attractive features in the construction of classifiers. However, its results can be enhanced even more if other data reduction techniques, such as instance selection, are considered. In this work, a hybrid evolutionary algorithm for data reduction, using both instance and feature selection, is presented. A global process of instance selection, carried out by a steady-state genetic algorithm, is combined with a fuzzy rough set based feature selection process, which searches for the most interesting features to enhance both the evolutionary search process and the final preprocessed data set. The experimental study, the results of which have been contrasted through nonparametric statistical tests, shows that our proposal obtains high reduction rates on training sets which greatly enhance the behavior of the nearest neighbor classifier.
Evolutionary Proposals
L. I. Kuncheva, Editing for the k-Nearest Neighbors Rule by a Genetic Algorithm. Pattern Recognition Letters 16 (1995) 809-814 doi: 10.1016/0167-8655(95)00047-K ![]()
Abstract: A genetic algorithm is applied for selecting a reference set for the k-Nearest Neighbors rule. The performance has been evaluated on a medical data set by the rotation method. The results are commented together with those obtained with the standard k-NN, random selection, Wilson's technique, and the MULTIEDIT algorithm.
S.-Y. Ho, C.-C. Liu, S. Liu, Design of an Optimal Nearest Neighbor Classifier Using an Intelligent Genetic Algorithm. Pattern Recognition Letters 23:13 (2002) 1495-1503 doi: 10.1016/S0167-8655(02)00109-5 ![]()
Abstract: The goal of designing an optimal nearest neighbor classifier is to maximize the classification accuracy while minimizing the sizes of both the reference and feature sets. A novel intelligent genetic algorithm (IGA) superior to conventional GAs in solving large parameter optimization problems is used to effectively achieve this goal. It is shown empirically that the IGA-designed classifier outperforms existing GA-based and non-GA-based classifiers in terms of classification accuracy and total number of parameters of the reduced sets.
J.R. Cano, F. Herrera, M. Lozano. Using Evolutionary Algorithms as Instance Selection for Data Reduction in KDD: An Experimental Study. IEEE Transactions on Evolutionary Computation, 7:6 (2003) 561-575 doi: 10.1109/TEVC.2003.819265 ![]()
Abstract: Evolutionary algorithms are adaptive methods based on natural evolution that may be used for search and optimization. As data reduction in knowledge discovery in databases (KDDs) can be viewed as a search problem, it could be solved using evolutionary algorithms (EAs). In this paper, we have carried out an empirical study of the performance of four representative EA models in which we have taken into account two different instance selection perspectives, the prototype selection and the training set selection for data reduction in KDD. This paper includes a comparison between these algorithms and other nonevolutionary instance selection algorithms. The results show that the evolutionary instance selection algorithms consistently outperform the nonevolutionary ones, the main advantages being: better instance reduction rates, higher classification accuracy, and models that are easier to interpret.
F. Fernández and P. Isasi, Evolutionary design of nearest prototype classifiers. Journal of Heuristics 10:4 (2004) 431–454 doi: 10.1023/B:HEUR.0000034715.70386.5b ![]()
Abstract: In pattern classification problems, many works have been carried out with the aim of designing good classifiers from different perspectives. These works achieve very good results in many domains. However, in general they are very dependent on some crucial parameters involved in the design. These parameters have to be found by a trial and error process or by some automatic methods, like heuristic search and genetic algorithms, that strongly decrease the performance of the method. For instance, in nearest prototype approaches, main parameters are the number of prototypes to use, the initial set, and a smoothing parameter. In this work, an evolutionary approach based on Nearest Prototype Classifier (ENPC) is introduced where no parameters are involved, thus overcoming all the problems that classical methods have in tuning and searching for the appropiate values. The algorithm is based on the evolution of a set of prototypes that can execute several operators in order to increase their quality in a local sense, and with a high classification accuracy emerging for the whole classifier. This new approach has been tested using four different classical domains, including such artificial distributions as spiral and uniform distibuted data sets, the Iris Data Set and an application domain about diabetes. In all the cases, the experiments show successfull results, not only in the classification accuracy, but also in the number and distribution of the prototypes achieved.
U. Garain, Prototype reduction using an artificial immune model. Pattern Analysis and Applications 11:3-4 (2008) 353-363 doi: 10.1007/s10044-008-0106-1 ![]()
Abstract: Artificial immune system (AIS)-based pattern classification approach is relatively new in the field of pattern recognition. The study explores the potentiality of this paradigm in the context of prototype selection task that is primarily effective in improving the classification performance of nearest-neighbor (NN) classifier and also partially in reducing its storage and computing time requirement. The clonal selection model of immunology has been incorporated to condense the original prototype set, and performance is verified by employing the proposed technique in a practical optical character recognition (OCR) system as well as for training and testing of a set of benchmark databases available in the public domain. The effect of control parameters is analyzed and the efficiency of the method is compared with another existing techniques often used for prototype selection. In the case of the OCR system, empirical study shows that the proposed approach exhibits very good generalization ability in generating a smaller prototype library from a larger one and at the same time giving a substantial improvement in the classification accuracy of the underlying NN classifier. The improvement in performance has been statistically verified. Consideration of both OCR data and public domain datasets demonstrate that the proposed method gives results better than or at least comparable to that of some existing techniques.
S. García, J.R. Cano, F. Herrera. A Memetic Algorithm for Evolutionary Prototype Selection: A Scaling Up Approach. Pattern Recognition, 41:8 (2008) 2693-2709 doi: 10.1016/j.patcog.2008.02.006 ![]()
Abstract: Prototype selection problem consists of reducing the size of databases by removing samples that are considered noisy or not influential on nearest neighbour classification tasks. Evolutionary algorithms have been used recently for prototype selection showing good results. However, due to the complexity of this problem when the size of the databases increases, the behaviour of evolutionary algorithms could deteriorate considerably because of a lack of convergence. This additional problem is known as the scaling up problem. Memetic algorithms are approaches for heuristic searches in optimization problems that combine a population-based algorithm with a local search. In this paper, we propose a model of memetic algorithm that incorporates an ad hoc local search specifically designed for optimizing the properties of prototype selection problem with the aim of tackling the scaling up problem. In order to check its performance, we have carried out an empirical study including a comparison between our proposal and previous evolutionary and non-evolutionary approaches studied in the literature. The results have been contrasted with the use of non-parametric statistical procedures and show that our approach outperforms previously studied methods, especially when the database scales up.
R. Gil-Pita, X. Yao, Evolving Edited K-Nearest Neighbor Classifiers. International Journal of Neural Systems 18:6 (2008) 459-467 doi: 10.1142/S0129065708001725 ![]()
Abstract: The k-nearest neighbor method is a classifier based on the evaluation of the distances to each pattern in the training set. The edited version of this method consists of the application of this classifier with a subset of the complete training set in which some of the training patterns are excluded, in order to reduce the classification error rate. In recent works, genetic algorithms have been successfully applied to determine which patterns must be included in the edited subset. In this paper we propose a novel implementation of a genetic algorithm for designing edited k-nearest neighbor classifiers. It includes the definition of a novel mean square error based fitness function, a novel clustered crossover technique, and the proposal of a fast smart mutation scheme. In order to evaluate the performance of the proposed method, results using the breast cancer database, the diabetes database and the letter recognition database from the UCI machine learning benchmark repository have been included. Both error rate and computational cost have been considered in the analysis. Obtained results show the improvement achieved by the proposed editing method.
L. Nanni and A. Lumini, Particle swarm optimization for prototype reduction. Neurocomputing, 72:4-6 (2008) 1092–1097 doi: 10.1016/j.neucom.2008.03.008 ![]()
Abstract: The problem addressed in this paper concerns the prototype reduction for a nearest-neighbor classifier. An efficient method based on particle swarm optimization is proposed here for finding a good set of prototypes. Starting from an initial random selection of a small number of training patterns, we generate a set of prototypes, using the particle swarm optimization, which minimizes the error rate on the training set. To improve the classification performance, during the training phase the prototype generation is repeated N times, then each of the resulting N sets of prototypes is used to classify each test pattern, and finally these N classification results are combined by the ‘‘vote rule’’. The performance improvement with respect to the state-of-the-art approaches is validated through experiments with several benchmark datasets.
A. Cervantes, I. M. Galván, and P. Isasi, AMPSO: A new particle swarm method for nearest neighborhood classification. IEEE Transactions on Systems, Man, and Cybernetics - Part B: Cybernetics 39:5 (2009) 1082-1091 doi: 10.1109/TSMCB.2008.2011816 ![]()
Abstract: Nearest prototype methods can be quite successful on many pattern classification problems. In these methods, a collection of prototypes has to be found that accurately represents the input patterns. The classifier then assigns classes based on the nearest prototype in this collection. In this paper, we first use the standard particle swarm optimizer (PSO) algorithm to find those prototypes. Second, we present a new algorithm, called adaptive Michigan PSO (AMPSO) in order to reduce the dimension of the search space and provide more flexibility than the former in this application. AMPSO is based on a different approach to particle swarms as each particle in the swarm represents a single prototype in the solution. The swarm does not converge to a single solution; instead, each particle is a local classifier, and the whole swarm is taken as the solution to the problem. It uses modified PSO equations with both particle competition and cooperation and a dynamic neighborhood. As an additional feature, in AMPSO, the number of prototypes represented in the swarm is able to adapt to the problem, increasing as needed the number of prototypes and classes of the prototypes that make the solution to the problem. We compared the results of the standard PSO and AMPSO in several benchmark problems from the University of California, Irvine, data sets and find that AMPSO always found a better solution than the standard PSO. We also found that it was able to improve the results of the Nearest Neighbor classifiers, and it is also competitive with some of the algorithms most commonly used for classification.
I. Triguero, S. García and F.Herrera, IPADE: Iterative Prototype Adjustment for Nearest Neighbor Classification. IEEE Transactions on Neural Networks 21:12 (2010) 1984-1990. COMPLEMENTARY MATERIAL to the paper here: datasets, experimental results and source codes, doi: 10.1109/TNN.2010.2087415 ![]()
Abstract: Nearest prototype methods are a successful trend of many pattern classification tasks. However, they present several shortcomings such as time response, noise sensitivity, and storage requirements. Data reduction techniques are suitable to alleviate these drawbacks. Prototype generation is an appropriate process for data reduction, which allows the fitting of a dataset for nearest neighbor (NN) classification. This brief presents a methodology to learn iteratively the positioning of prototypes using real parameter optimization procedures. Concretely, we propose an iterative prototype adjustment technique based on differential evolution. The results obtained are contrasted with nonparametric statistical tests and show that our proposal consistently outperforms previously proposed methods, thus becoming a suitable tool in the task of enhancing the performance of the NN classifier.
I. Triguero, S. García and F.Herrera, Differential evolution for optimizing the positioning of prototypes in nearest neighbor classification. Pattern Recognition 44:4 (2011) 901-916, doi: 10.1016/j.patcog.2010.10.020 ![]()
Abstract: Nearest neighbor classification is one of the most used and well known methods in data mining. Its simplest version has several drawbacks, such as low efficiency, high storage requirements and sensitivity to noise. Data reduction techniques have been used to alleviate these shortcomings. Among them, prototype selection and generation techniques have been shown to be very effective. Positioning adjustment of prototypes is a successful trend within the prototype generation methodology. Evolutionary algorithms are adaptive methods based on natural evolution that may be used for searching and optimization. Positioning adjustment of prototypes can be viewed as an optimization problem, thus it can be solved using evolutionary algorithms. This paper proposes a differential evolution based approach for optimizing the positioning of prototypes. Specifically, we provide a complete study of the performance of four recent advances in differential evolution. Furthermore, we show the good synergy obtained by the combination of a prototype selection stage with an optimization of the positioning of prototypes previous to nearest neighbor classification. The results are contrasted with non-parametrical statistical tests and show that our proposals outperform previously proposed methods
N. García-Pedrajas, J. A. Romero Del Castillo, and D. Ortiz-Boyer, A Cooperative Coevolutionary Algorithm for Instance Selection for Instance-Based Learning. Machine Learning 78:3 (2010) 381-420 doi: 10.1007/s10044-008-0106-1 ![]()
Abstract: This paper presents a cooperative evolutionary approach for the problem of instance selection for instance based learning. The model presented takes advantage of one of the recent paradigms in the field of evolutionary computation: cooperative coevolution. This paradigm is based on a similar approach to the philosophy of divide and conquer. In our method, the training set is divided into several subsets that are searched independently. A population of global solutions relates the search in different subsets and keeps track of the best combinations obtained. The proposed model has the advantage over standard methods in that it does not rely on any specific distance metric or classifier algorithm. Additionally, the fitness function of the individuals considers both storage requirements and classification accuracy, and the user can balance both objectives depending on his/her specific needs, assigning different weights to each one of these two terms. The method also shows good scalability when applied to large datasets. The proposed model is favorably compared with some of the most successful standard algorithms, IB3, ICF and DROP3, with a genetic algorithm using CHC method, and with four recent methods of instance selection, MSS, entropy-based instance selection, IMOEA and LVQPRU. The comparison shows a clear advantage of the proposed algorithm in terms of storage requirements, and is, at least, as good as any of the other methods in terms of testing error. A large set of 50 problems from the UCI Machine Learning Repository is used for the comparison. Additionally, a study of the effect of instance label noise is carried out, showing the robustness of the proposed algorithm. The proposed model is favorably compared with some of the most successful standard algorithms, IB3, ICF and DROP3, with a genetic algorithm using CHC method, and with four recent methods of instance selection, MSS, entropy-based instance selection, IMOEA and LVQPRU. The comparison shows a clear advantage of the proposed algorithm in terms of storage requirements, and is, at least, as good as any of the other methods in terms of testing error. A large set of 50 problems from the UCI Machine Learning Repository is used for the comparison. Additionally, a study of the effect of instance label noise is carried out, showing the robustness of the proposed algorithm. The major contribution of our work is showing that cooperative coevolution can be used to tackle large problems taking advantage of its inherently modular nature. We show that a combination of cooperative coevolution together with the principle of divide-and-conquer can be very effective both in terms of improving performance and in reducing computational cost.
SCI2S Related Approaches
Stratification methods
J.R. Cano, F. Herrera, M. Lozano, Stratification for Scaling Up Evolutionary Prototype Selection. Pattern Recognition Letters, 26, (2005), 953-963 doi: 10.1016/j.patrec.2004.09.043 ![]()
Abstract: Evolutionary algorithms has been recently used for prototype selection showing good results. An important problem that we can find is the scaling up problem that appears evaluating the Evolutionary Prototype Selection algorithms in large size data sets. In this paper, we offer a proposal to solve the drawbacks introduced by the evaluation of large size data sets using evolutionary prototype selection algorithms. In order to do this we have proposed a combination of stratified strategy and CHC as representative evolutionary algorithm model. This study includes a comparison between our proposal and other non-evolutionary prototype selection algorithms combined with the stratified strategy. The results show that stratified evolutionary prototype selection consistently outperforms the non-evolutionary ones, the main advantages being: better instance reduction rates, higher classification accuracy and reduction in resources consumption.
J. Derrac, S. García, F. Herrera, Stratified Prototype Selection based on a Steady-State Memetic Algorithm: A Study of scalability. Memetic Computing 2:3 (2010) 183-199. doi: 10.1007/s12293-010-0048-1 ![]()
Abstract: Prototype selection (PS) is a suitable data reduction process for refining the training set of a data mining algorithm. Performing PS processes over existing datasets can sometimes be an inefficient task, especially as the size of the problem increases. However, in recent years some techniques have been developed to avoid the drawbacks that appeared due to the lack of scalability of the classical PS approaches. One of these techniques is known as stratification. In this study, we test the combination of stratification with a previously published steady-state memetic algorithm for PS in various problems, ranging from 50,000 to more than 1 million instances. We perform a comparison with some well-known PS methods, and make a deep study of the effects of stratification in the behavior of the selected method, focused on its time complexity, accuracy and convergence capabilities. Furthermore, the trade-off between accuracy and efficiency of the proposed combination is analyzed, concluding that it is a very suitable option to perform PS tasks when the size of the problem exceeds the capabilities of the classical PS methods.
Imbalanced Data
S. García, F. Herrera Evolutionary Under-Sampling for Classification with Imbalanced Data Sets: Proposals and Taxonomy. Evolutionary Computation 17:3 (2009) 275-306 doi: 10.1162/evco.2009.17.3.275 ![]()
Abstract: Learning with imbalanced data is one of the recent challenges in machine learning. Various solutions have been proposed in order to find a treatment for this problem, such as modifying methods or the application of a preprocessing stage. Within the preprocessing focused on balancing data, two tendencies exist: reduce the set of examples (undersampling) or replicate minority class examples (oversampling). Undersampling with imbalanced datasets could be considered as a prototype selection procedure with the purpose of balancing datasets to achieve a high classification rate, avoiding the bias toward majority class examples. Evolutionary algorithms have been used for classical prototype selection showing good results, where the fitness function is associated to the classification and reduction rates. In this paper, we propose a set of methods called evolutionary undersampling that take into consideration the nature of the problem and use different fitness functions for getting a good trade-off between balance of distribution of classes and performance. The study includes a taxonomy of the approaches and an overall comparison among our models and state of the art undersampling methods. The results have been contrasted by using nonparametric statistical procedures and show that evolutionary undersampling outperforms the nonevolutionary models when the degree of imbalance is increased.
Data complexity
S. García, J.R. Cano, E. Bernadó-Mansilla, F. Herrera, Diagnose of Effective Evolutionary Prototype Selection using an Overlapping Measure. International Journal of Pattern Recognition and Artificial Intelligence 23:8 (2009) 1527-1548 doi: 10.1142/S0218001409007727 ![]()
Abstract: Evolutionary prototype selection has shown its effectiveness in the past in the prototype selection domain. It improves in most of the cases the results offered by classical prototype selection algorithms but its computational cost is expensive. In this paper, we analyze the behavior of the evolutionary prototype selection strategy, considering a complexity measure for classification problems based on overlapping. In addition, we have analyzed different k values for the nearest neighbour classifier in this domain of study to see its influence on the results of PS methods. The objective consists of predicting when the evolutionary prototype selection is effective for a particular problem, based on this overlapping measure.
Hyperrectangles
S. García, J. Derrac, J. Luengo, C.J. Carmona, F. Herrera, Evolutionary Selection of Hyperrectangles in Nested Generalized Exemplar Learning. Applied Soft Computing 11:3 (2011) 3032-3045 doi: 10.1016/j.asoc.2010.11.030 ![]()
Abstract: The nested generalized exemplar theory accomplishes learning by storing objects in Euclidean n-space, as hyperrectangles. Classification of new data is performed by computing their distance to the nearest “generalized exemplar” or hyperrectangle. This learning method allows the combination of the distance- based classification with the axis-parallel rectangle representation employed in most of the rule-learning systems. In this paper, we propose the use of evolutionary algorithms to select the most influential hyperrectangles to obtain accurate and simple models in classification tasks. The proposal has been compared with the most representative models based on hyperrectangle learning; such as the BNGE, RISE, INNER, and SIA genetics based learning approach. Our approach is also very competitive with respect to classical rule induction algorithms such as C4.5Rules and RIPPER. The results have been contrasted through non-parametric statistical tests over multiple data sets and they indicate that our approach outperforms them in terms of accuracy requiring a lower number of hyperrectangles to be stored, thus obtaining simpler models than previous NGE approaches. Larger data sets have also been tackled with promising outcomes.
S. García, J. Derrac, I. Triguero, C.J. Carmona, F. Herrera, Evolutionary-Based Selection of Generalized Instances for Imbalanced Classification. Knowledge Based Systems 25:1 (2012) 3-12 doi: 10.1016/j.knosys.2011.01.012 ![]()
Abstract: In supervised classification, we often encounter many real world problems in which the data do not have an equitable distribution among the different classes of the problem. In such cases, we are dealing with the so-called imbalanced data sets. One of the most used techniques to deal with this problem consists of preprocessing the data previously to the learning process. This paper proposes a method belonging to the family of the nested generalized exemplar that accomplishes learning by storing objects in Euclidean n-space. Classification of new data is performed by computing their distance to the nearest generalized exemplar. The method is optimized by the selection of the most suitable generalized exemplars based on evolutionary algorithms. An experimental analysis is carried out over a wide range of highly imbalanced data sets and uses the statistical tests suggested in the specialized literature. The results obtained show that our evolutionary proposal outperforms other classic and recent models in accuracy and requires to store a lower number of generalized examples.
Hybrid methods
J. Derrac, S. García, F. Herrera, Instance and Feature Selection based on Cooperative Coevolution with Nearest Neighbor Rule. Pattern Recognition 43:6 (2010) 2082-2105 doi: 10.1016/j.patcog.2009.12.012 ![]()
Abstract: Feature and instance selection are two effective data reduction processes which can be applied to classification tasks obtaining promising results. Although both processes are defined separately, it is possible to apply them simultaneously. This paper proposes an evolutionary model to perform feature and instance selection in nearest neighbor classification. It is based on cooperative coevolution, which has been applied to many computational problems with great success. The proposed approach is compared with a wide range of evolutionary feature and instance selection methods for classification. The results contrasted through non-parametric statistical tests show that our model outperforms previously proposed evolutionary approaches for performing data reduction processes in combination with the nearest neighbor rule.
J. Derrac, C. Cornelis, S. García, F. Herrera, Enhancing evolutionary instance selection algorithms by means of fuzzy rough set based feature selection. Information Sciences 186 (2012) 73–92 doi: 10.1016/j.ins.2011.09.027 ![]()
Abstract: In recent years, fuzzy rough set theory has emerged as a suitable tool for performing feature selection. Fuzzy rough feature selection enables us to analyze the discernibility of the attributes, highlighting the most attractive features in the construction of classifiers. However, its results can be enhanced even more if other data reduction techniques, such as instance selection, are considered. In this work, a hybrid evolutionary algorithm for data reduction, using both instance and feature selection, is presented. A global process of instance selection, carried out by a steady-state genetic algorithm, is combined with a fuzzy rough set based feature selection process, which searches for the most interesting features to enhance both the evolutionary search process and the final preprocessed data set. The experimental study, the results of which have been contrasted through nonparametric statistical tests, shows that our proposal obtains high reduction rates on training sets which greatly enhance the behavior of the nearest neighbor classifier.
Prototype Reduction Visibility at the Web of Science
The ISI Web of Science provides seamless access to current and retrospective multidisciplinary information from approximately 8,700 of the most prestigious, high impact research journals in the world. Web of Science also provides a unique search method, cited reference searching. With it, users can navigate forward, backward, and through the literature, searching all disciplines and time spans to uncover all the information relevant to their research. Users can also navigate to electronic full-text journal articles (http://scientific.thomson.com/products/wos/).
In the link of "Advanced Search", we consider the following query, using PR as a 'Topic' field for the search:
PR= ("Prototype Selection" OR "Prototype Generation" OR "Prototype Abstraction" OR "Prototype Reduction" OR ("Instance Selection" AND "Nearest Neighbor") OR ("Instance Generation" AND "Nearest Neighbor") OR ("Instance Abstraction" AND "Nearest Neighbor") OR ("Data Reduction" AND "Instance Selection") OR ("Data Reduction" AND "Instance Generation") OR ("Data Reduction" AND "Instance Abstraction") OR ("Data Reduction" AND "Nearest Neighbor"))
The numerical results of the query are:
Date of analysis: September 7th, 2011
Number of papers: 317
Sum of the times cited: 2,651
Average citations per item: 8.36
Figures 5 and 6 show the number of publications and citations per year.
|
|
|
|
Fig. 5. Publications in PR per year (Web of Science) |
Fig. 6. Number of citations per year (Web of Science) |
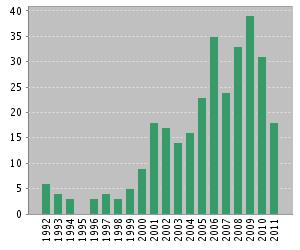
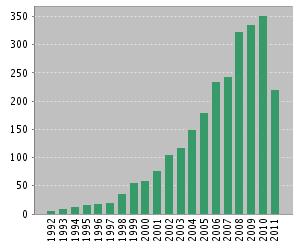
We observe an increasing number of publications with more than 20 papers per year since 2005. The number of citations shows a similar increasing trend (more than 150 citations per year). Therefore, it can be seen that the PR field is still in a growing stage where more approaches are presented every year, aiming to improve the performance of the techniques developed so far.
Software and Algorithm Implementations
|
Knowledge Extraction based on Evolutionary Learning (KEEL): KEEL is a software tool to assess evolutionary algorithms for Data Mining problems including regression, classification, clustering, pattern mining and so on. It contains a big collection of classical knowledge extraction algorithms, preprocessing techniques (instance selection, feature selection, discretization, imputation methods for missing values, etc.), Computational Intelligence based learning algorithms, including evolutionary rule learning algorithms based on different approaches (Pittsburgh, Michigan and IRL, ...), and hybrid models such as genetic fuzzy systems, evolutionary neural networks, etc. It allows us to perform a complete analysis of any learning model in comparison to existing ones, including a statistical test module for comparison. Moreover, KEEL has been designed with a double goal: research and educational. This software tool will be available as open source software this summer. For more information about this tool, please refer to the following publication: |
J. Alcalá-Fdez, L. Sánchez, S. García, M.J. del Jesus, S. Ventura, J.M. Garrell, J. Otero, C. Romero, J. Bacardit, V.M. Rivas, J.C. Fernández, F. Herrera , KEEL: A Software Tool to Assess Evolutionary Algorithms for Data Mining Problems. Soft Computing, 13:3 (2009) 307-318. doi: 10.1007/s00500-008-0323-y ![]()
|
KEEL Data Set Repository (KEEL-dataset): KEEL-dataset repository is devoted to the data sets in KEEL format which can be used with the software and provides: A detailed categorization of the considered data sets and a description of their characteristics. Tables for the data sets in each category have been also created; A descriptions of the papers which have used the partitions of data sets available in the KEEL-dataset repository. These descriptions include results tables, the algorithms used and additional material. For more information about this repository, please refer to the following publication: |
J. Alcalá-Fdez, A. Fernández, J. Luengo, J. Derrac, S. García, L. Sánchez, F. Herrera, KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework. Journal of Multiple-Valued Logic and Soft Computing 17:2-3 (2011) 255-287. doi: 10.1007/s00500-008-0323-y ![]()
Recent and forthcoming approaches
Prototype Selection and Prototype Generation are two lively research fields. As time goes by, new methods are developed following the basic guidelines that any Prototype Reduction algorithm should accomplish. These new methods often offer to the comunity different viewpoints to the problem, as well as better and more efficient approaches.
In this section, those approaches proposed later than the publishing of the two SCI2S surveys on Prototype Reduction are referenced, highlighting their categorization within the proposed taxonomies. In addition, a technical report with a brief description of their main characteristics is provided.
As this section is intended to growth with the development of new approaches through the following years, suggestions of new approaches for this survey are welcome (with only one requirement: new approaches must be already published in an international journal or well-known conference). Please, contact with J. Derrac or I. Triguero if you wish to add a new Prototype Reduction method to this website.
J. Derrac, I. Triguero>, S. García, and F.Herrera, Survey of New Approaches on Prototype Selection and Generation.![]()
Prototype Selection
- Condensation - Incremental
- Complete Cross Validation Functional Algorithm 2 (CCV-2)
M. N. Ivanov, Prototype Sample Selection Based on Minimization of the Complete Cross Validation Functional. Pattern Recognition and Image Analysis 20:4 (2010) 427–437, doi: 10.1134/S1054661810040024
- Complete Cross Validation Functional Algorithm 2 (CCV-2)
- Condensation - Decremental< > Complete Cross Validation Functional Algorithm 1 (CCV-1)
M. N. Ivanov, Prototype Sample Selection Based on Minimization of the Complete Cross Validation Functional. Pattern Recognition and Image Analysis 20:4 (2010) 427–437, doi: 10.1134/S1054661810040024
Instance Selection by using Polar Grids (ISPG)
Y. Sang, Z. Yi, Instance Selection by using Polar Grids. 2010 3rd International Coriference on Advanced Computer Theory and Engineering (2010) V3-344 - V3-348 doi: 10.1109/ICACTE.2010.5579549
- Edition - Decremental< > Instances Selection algorithm based on Classification Contribution Function (ISCC)
Y. Cai, B. Wu, Y. He, Y. Zhang, A New Instance Selection Algorithm Based on Contribution for Nearest Neighbour Classification. Ninth International Conference on Machine Learning and Cybernetics (2010) 155-160, doi: 10.1109/ICMLC.2010.5581074
Instance Selection based on Local SVM (LSVM)
N. Segata, E. Blanzieri, S. J. Delany, P. Cunningham, Noise Reduction for Instance-Based Learning with a Local Maximal Margin Approach. Journal of Intelligent Information Systems 35 (2010) 301–331, doi: 10.1007/s10844-009-0101-z
- Edition - Batch
- Reward–Punishment Editing (RP-Editing)
A. Franco, D. Maltoni, L. Nanni, Data Pre-Processing Through Reward–Punishment Editing. Pattern Analysis and Applications 13 (2010) 367–381, doi: 10.1007/s10044-010-0182-x
- Reward–Punishment Editing (RP-Editing)
- Hybrid - Mixed+Wrapper< >Instinctive Mating Genetic Algorithm with (Correct My Wrongs distance/Hamming distance/Multiple populations) (IM-CMW, IM-H, IM-MP)
T. Quirino, M. Kubat, N. J. Bryan, Instinct-Based Mating in Genetic Algorithms Applied to the Tuning of 1-NN Classifiers. IEEE Transactions on Knowledge and Data Engineering 22:12 (2010) 1724-1737, doi: 10.1109/TKDE.2009.211
Supervised and Nonparametric Evaluation of Sets of Instances (Eva)
S. Ferrandiz, M. Boullé, Bayesian instance selection for the nearest neighbor rule. Machine Learning 81 (2010) 229–256, doi: 10.1007/s10994-010-5170-2
Local Search with Tabu List for Instance Selection (LS+TL)
I. Czarnowski, Cluster-Based Instance Selection for Machine Classification. Knowledge and Information Systems, In press (2011), doi: 10.1007/s10115-010-0375-z
Sequential Reduction Algorithm (SeqRA)
M. Raniszewski, Sequential Reduction Algorithm for Nearest Neighbor Rule. 2010 International Conference on Computer Vision and Graphics, Part II, Lecture Notes in Computer Science 6375 (2010) 219–226, doi: 10.1007/978-3-540-93905-4_27
- Hybrid - Fixed+Wrapper
- A Genetic Algorithm for Prototype Selection with Dissimilarity Representation (GA+LDA)
Y. Plasencia-Calaña, E. García-Reyes, M. Orozco-Alzate, R. P.W. Duin, Prototype Selection for Dissimilarity Representation by a Genetic Algorithm. 2010 International Conference on Pattern Recognition (2010) 177-180, doi: 10.1109/ICPR.2010.52
- A Genetic Algorithm for Prototype Selection with Dissimilarity Representation (GA+LDA)
Prototype Generation
- Positioning Adjustment - Condensation - Fixed
- Weighted LVQ (WLVQ)
M. Blachnik, W. Duch, Improving Accuracy of LVQ Algorithm by Instance Weighting. 2010 International Conference on Artificial Neural Networks, Lecture Notes in Computer Science 6354 (2010) 257-266, doi: 10.1007/978-3-642-15825-4_31
- Weighted LVQ (WLVQ)
- Positioning Adjustment - Edition - Mixed - Semi-Wrapper
- Editing based on a Fast Two-String Median Computation (JJWilson)
J. I. Abreu, J. R. Rico-Juan, A New Editing Scheme Based on a Fast Two-String Median Computation Applied to OCR. Structural, Syntactic, and Statistical Pattern Recognition, Lecture Notes in Computer Science 6218 (2010) 748-756, doi: 10.1007/978-3-642-14980-1_74
- Editing based on a Fast Two-String Median Computation (JJWilson)
- Centroids - Hybrid - Mixed
- Class Boundary Preserving Algorithm (CBP)
K. Nikolaidis, J. Y. Goulermas, Q. H. Wu, A Class Boundary Preserving Algorithm for Data Condensation. Pattern Recognition 44 (2011) 704–715,doi: 10.1016/j.patcog.2010.08.014
- Class Boundary Preserving Algorithm (CBP)
- Space Splitting - Hybrid
- Instance Seriation for Prototype Abstraction (IPSA)
K. Nikolaidis, E. Rodriguez, J. Y. Goulermas, Q. H. Wu, Instance Seriation for Prototype Abstraction. 2010 IEEE Fifth International Conference on Bio-Inspired Computing: Theories and Applications (2010) 1351-1355, doi: 10.1109/BICTA.2010.5645066
- Instance Seriation for Prototype Abstraction (IPSA)