
 |
 |
 |
 |
 |
 |
 |
| |
 |
|
Visits since 05/11/2005:
419503 
|
| |
Table of Contents
KEEL Reference Manual- - Basic KEEL developement guidelines
- - Method Description files
- - Method Configuration files
- - Data files
- - Output files
- - Use Case files
- - API Dataset
Basic KEEL developement guidelines
Introduction
The purpose of this document is to describe some basic concepts about the structure of KEEL (Knowledge Extraction based on Evolutionary Learning) and the format of its internal files.
The aim of this section is to present the KEEL framework, describing some guidelines to help a potential developer to build new methods inside the KEEL environment. The next sections will deal with the formats of the configuration files of KEEL (including data sets files, method descriptions and so on). Finally, the last section describes the API dataset of KEEL, which is used to handle and check the data sets files.
Developing a new method
Before to start the task of developing a new method inside of KEEL environment, some operations have to be performed in order to fully integrate it. By following this guidelines, a developer can left all the input/output operations to be accomplished by KEEL environment, focusing its efforts in the construction of the method itself.
The steps needed to complete the integration of a new method in KEEL are:
- Reading of the configuration file.
- Development of the method.
- Writing the output files.
- Registering the method in KEEL.
- Making the use case files.
- Building the executables of the method.
Reading of the configuration file
The KEEL methods only accept one parameter: The name and path of a configuration file. A typical main class of a method can be the following:
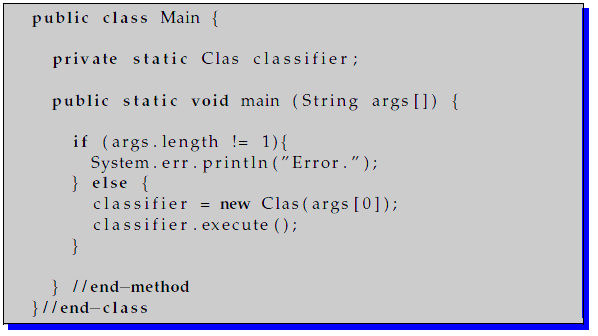
The configuration file contains information about the input and output files of the method. In addition, it contains the values for all the parameters defined. A full description of the configuration files can be found in the configuration files section.
By interpreting this file, the method should be able to acquire the correct values of its parameters, including the seed to initialize the random number generator if the method needs it.
Also, the names and paths of the input and output files are specified inside. Usually, a KEEL method employs two input data files: The training file, containing the data set which should be employed in the train phase of the method, and the test file, containing the data set which should be employed in the test phase. In addition, any method excepting the preprocessing methods and the test methods specify a third file, the validation file. This file contains a copy of the original dataset of the experiment, which can be used in comparisons with the train data.
The format of the data files is explained in data files section. These files must be handled with care, because they will be employed not only by the method, but also by the KEEL API dataset (see API Dataset section) in order to load and check the data in an efficient way.
Any KEEL method must define at least two output files: A train output file and a test output file. In addition, it is possible to define additional output files in the configuration file. They will be explained in the next subsections of this guide.
Developement of the method
The development of the method can be done in any programming environment. The only requirements are: The method must be developed with the Java programming language, and it must employ a package structure whose root will be the keel/src directory, where the sources of any KEEL method are located.
Writing the output files
As is explained before, at least two output files must be produced by the method (the train output file, and the test output file). Its format is described in output filessection.
If it is desired to employ additional output files, they also can be created at the end of the execution on the method. These additional files will get its name from the configuration file. Also, it is important to note that, in order to let the KEEL GUI automatically generate the names of these files, the number of additional outputs of the methods must be placed in the corresponding method description file.
Registering the method in KEEL
When the method have been fully coded, it must be registered in the KEEL configuration files, to allow the KEEL GUI to employ the new method.
The first step is to create a method description file. The format of these files is fully described in method filessection.
The second step involves modifying the master description file of each category method. Currently, 11 categories are defined:
- Discretization
- Educational Methods
- Educational Preprocess
- Feature Selection
- Instance Selection
- Method
- Postprocess
- Preprocess
- Tests
- TransOthers
- Visualize
When the correct master description file have been found (please, ask to a KEEL project manager if it is not clear what file have to be modified), a new registry containing the definition of the method must be created. The KEEL master description file registers have the following structure:

The header is composed by four nodes:

- Name:
- The name of the method
- Family:
- The category of the method
- Jar File:
- The name of the Jar file which contains the method
- Problem Type:
- The class of problems which can manage the method. There are defined 4 classes:
- Classification, for supervised classification problems.
- Regression, for regression problems.
- Unsupervised, for unsupervised classification problems (e.g. clustering).
- Unspecified, for any problem (supervised classification, unsupervised classification or regression).
The input and output parts defines the types of data which the method is able to manage, both in input data and output data. Their fields must specify which types are allowed, by employing yes and no keywords. A description of the fields is shown as follows:
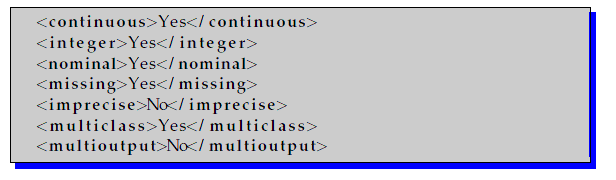
- Continuous:
- The method is able to work with continuous values.
- Integer:
- The method is able to work with integer values.
- Nominal:
- The method is able to work with nominal values.
- Missing:
- The method is able to handle missing values.
- Imprecise Value:
- The method is able to work with imprecise values.
- Multiclass:
- The method is able to work with problem which defines more than 2 classes.
- Multioutput:
- The method is able to work with data which defines more than 1 output for each instance.
When the header, input and output sections were completely defined, then the new registry can be place inside the corresponding master description file. Below is shown a valid example of registry:

Making the use case files
When developing a new method, it is important to document properly its functions and objectives. Also, the users should be able to look up relevant information about the method (a brief description, some references, the description of its parameters, etc.) when they select the method in KEEL.
To manage this information, the KEEL GUI defines the use case files, which are XML files containing all the relevant information needed to employ any KEEL method. A full description of the use case files can be found in use case files section.
Building the executables
When the method was fully developed, and its relevant configuration files have been created, the last step is to add it to the build.xml file (an ANT script file), so the new versions of KEEL could be able to build it inside the KEEL environment. The build.xml is a critical file, so it is not recommended to modify it without authorization of a KEEL project manager.
The build.xml changes dynamically with any new version of KEEL, thus its is not possible to fully describe its structure here. However, it is possible to describe which part of the file must be changed to allow the inclusion of new methods.
Firstly, the jar target must be found. It should have the following structure:

The jar target is composite by a great number of tasks, every one dealing with the construction of a jar file for each method. Inside this target, the construction of the new jar file must be described as another task. Here is a valid example:

The task must define the locations of the new jar file and their corresponding manifest file. Also, must include the files from the classes which compose the method. Also, the files from the imported classes are required to fully describing the task.
|
Copyright 2004-2018,
KEEL (Knowledge Extraction based on Evolutionary Learning)
About the Webmaster Team |

|