
 |
 |
 |
 |
 |
 |
 |
| |
 |
|
Visits since 05/11/2005:
419306 
|
| |
Table of Contents
KEEL Reference Manual- - Basic KEEL developement guidelines
- - Method Description files
- - Method Configuration files
- - Data files
- - Output files
- - Use Case files
- - API Dataset
Data files
In KEEL, the data sets are managed by plain ASCII text files, with the .dat extension. Usually, they are located under the ../dist/data directory, each one in its own folder (which also should contains the partitions created from the whole data set). In addition, preprocess methods will also create data files as its output, which will be placed on the ../datasets directory of its experiment.
This section describes the format employed to define them (which is fairly similar to WEKA arff format). Each KEEL data file is composed by 2 sections:
- Header
- Basic metadata describing the data set.
- Data
- Content of the dataset.
In both sections it is possible to insert comments, by employing the "%"character.
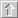
Header
The header is composed by the following metadata:

- @relation
- The name of the data set.
- @attribute
Describes one attribute of the data (a column). It is possible to define three different types of attributes:
- integer: @attribute <name> integer [min, max]
- real: @attribute <name> real [min, max]
- nominal: @attribute <name> [value1, value2, ..., valueN]
The <name> is the identifier of the attribute. Its maximum length allowed is 12 characters. The min and max values fon integer and real attributes, and the list of possible values for nominal attributes, are optional. If they are missing, the corresponding values will be extracted from the data by the KEEL data process module.
- @inputs
- Identifiers of the attributes which must be processed as inputs.
- @outputs
- Identifiers of the attributes which must be processed as outputs.
The @inputs and @outputs definitions are optional. If they are missing, all the attributes will be considered as input attributes, except the last, which will be considered as output attribute.
Data
The data instances are represented as rows of comma separated values, where each value corresponds to one attribute, in the order defined by the header. Missing or null values are defined as <null> or ?.
If the dataset corresponds to a classification problem, the output type must be nominal:
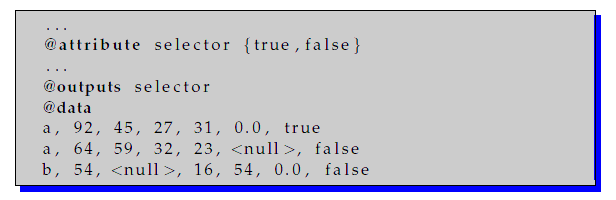
If the dataset corresponds to a regression problem, the output type must be real:
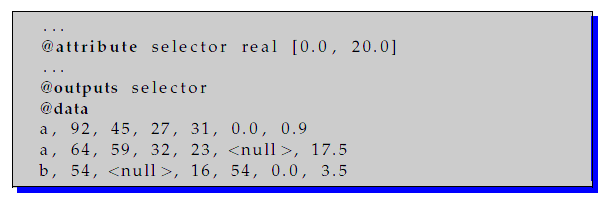
Example of use
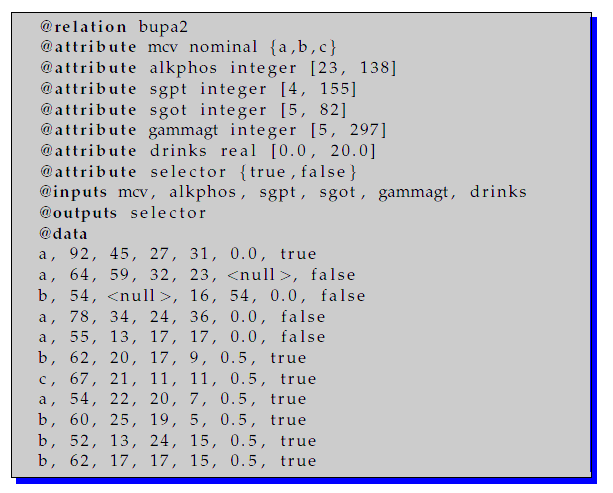
This is a valid example of a data file:
|
Copyright 2004-2018,
KEEL (Knowledge Extraction based on Evolutionary Learning)
About the Webmaster Team |

|