
Tackling the Problem of Classification with Noisy Data using Multiple Classifier Systems: Analysis of the Performance and Robustness
This Website contains the complementary material to the paper:
José A. Sáez, Mikel Galar, Julián Luengo, Francisco Herrera, Tackling the Problem of Classification with Noisy Data using Multiple Classifier Systems: Analysis of the Performance and Robustness. Information Sciences, 247 (2013) 1-20.
The web is organized according to the following summary:
Abstract
Traditional classifier learning algorithms build a unique classifier from the training data. Noisy data may deteriorate the performance of this classifier depending on the degree of sensitiveness to data corruptions of the learning method. In the literature, it is widely claimed that building several classifiers from noisy training data and combining their predictions is an interesting method of overcoming the individual problems produced by noise in each classifier. This statement is usually not supported by thorough empirical studies considering problems with different types and levels of noise. Furthermore, in noisy environments, the noise robustness of the methods can be more important than the performance results themselves and, therefore, it must be carefully studied. This paper aims to reach conclusions on such aspects focusing on the analysis of the behavior, in terms of performance and robustness, of several Multiple Classifier Systems against their individual classifiers when these are trained with noisy data. In order to accomplish this study, several classification algorithms, of varying noise robustness, will be chosen and compared with respect to their combination on a large collection of noisy datasets. The results obtained show that the success of the Multiple Classifier Systems trained with noisy data depends on the individual classifiers chosen, the decisions combination method and the type and level of noise present in the dataset, but also on the way of creating diversity to build the final system. In most of the cases, they are able to outperform all their single classification algorithms in terms of global performance, even though their robustness results will depend on the way of introducing diversity into the Multiple Classifier System.
Base Datasets
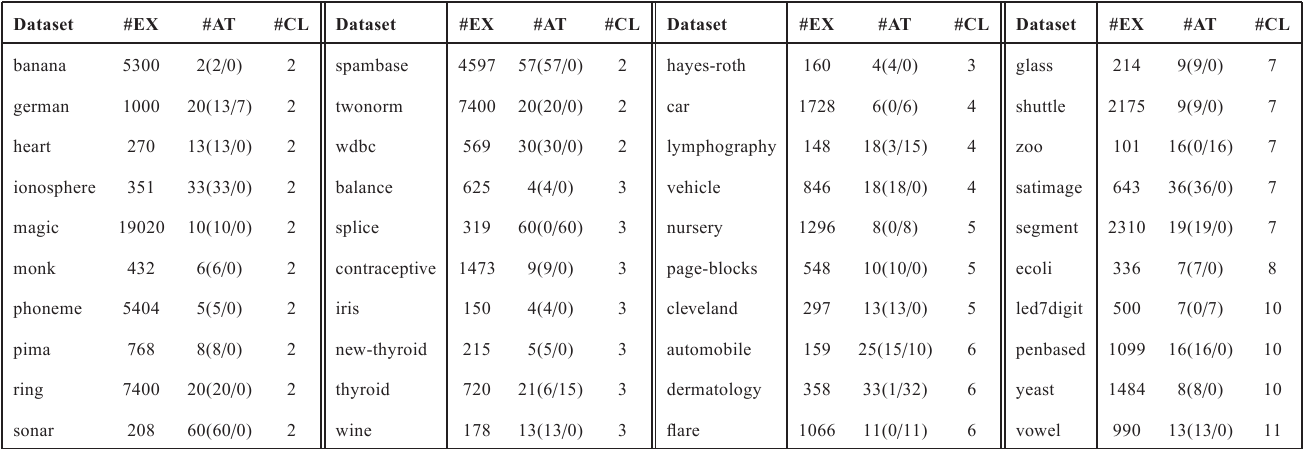
The experimentation is based on forty real-world classification problems from the KEEL dataset repository. Next table shows the datasets sorted by the number of classes (#CLA). Moreover, for each dataset, the number of examples (#EXA) and the number of attributes (#ATT), along with the number of numeric and nominal attributes are presented. Some of the largest datasets (nursery, page-blocks, penbased, satimage, splice and led7digit) were stratified at 10% in order to reduce the computational time required for training, given the large amount of executions. For datasets containing missing values (such as automobile or dermatology), instances with missing values were removed from the dataset before the partitioning.
You can also download all these datasets by clicking here: ![]()
Results of MCSs with Noisy Data
Datasets
![]() Random class noise scheme
Random class noise scheme![]() Pairwise class noise scheme
Pairwise class noise scheme![]() Random attribute noise scheme
Random attribute noise scheme![]() Gaussian attribute noise scheme
Gaussian attribute noise scheme
Results
| Base | MAJ | W-MAJ | NB | BKS | BagC4.5 |
|---|---|---|---|---|---|