
Statistical computation of feature weighting schemes through data estimation for nearest neighbor classifiers
This Website contains complementary material to the paper:
José A. Sáez, Joaquín Derrac, Julián Luengo, Francisco Herrera, Statistical computation of feature weighting schemes through data estimation for nearest neighbor classifiers. Pattern Recognition, submitted.
The web is organized according to the following summary:
Abstract
The Nearest Neighbor rule is one of the most successful classifiers in machine learning. However, it is very sensitive to noisy, redundant and irrelevant features, which may deteriorate its performance. Feature weighting methods try to overcome this problem by incorporating weights into the similarity function to increase or reduce the importance of each feature, according to how they behave in the classification task. This paper proposes a new feature weighting classifier, where the computation of the weights is based on a novel idea which combines imputation methods - used to estimate a new distribution of values for each feature based on the rest of the data - and the Kolmogorov-Smirnov nonparametric statistical test to measure the changes between the original and imputed distribution of values. This proposal is compared with classic and recent feature weighting methods. The experimental results show that it is an effective way of improving the performance of the Nearest Neighbor classifier, outperforming the rest of the classifiers considered in the comparisons.
Data sets
The following table shows the data sets considered in the paper:
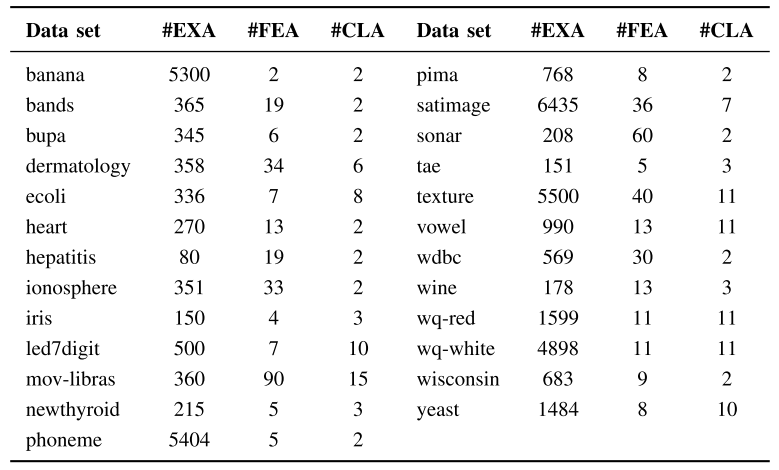
You can download all these datasets clicking here: ![]()
Performance results
In the following table you can download the files with the results using both a distribution optimally balanced stratified cross-validation (DOB-SCV) and a standard stratified cross-validation (SCV).
| Partitioning | Performance results | Statistical comparison |
|---|---|---|
| DOB-SCV | ||
| SCV |