|
KEEL (Knowledge Extraction based on Evolutionary Learning) is an open source (GPLv3) Java software tool that can be used for a large number of different knowledge data discovery tasks.
KEEL provides a simple GUI based on data flow to design experiments with different datasets and computational intelligence algorithms (paying special attention to evolutionary algorithms) in order to assess the behavior of the algorithms. It contains a wide variety of classical knowledge extraction algorithms, preprocessing techniques (training set selection, feature selection, discretization, imputation methods for missing values, among others), computational intelligence based learning algorithms, hybrid models, statistical methodologies for contrasting experiments and so forth. It allows to perform a complete analysis of new computational intelligence proposals in comparison to existing ones. Moreover, KEEL has been designed with a two-fold goal: research and educational.
If you want to refer to KEEL in a publication, please cite us using the following references:
KEEL description papers:
- J. Alcalá-Fdez, L. Sánchez, S. García, M.J. del Jesus, S. Ventura, J.M. Garrell, J. Otero, C. Romero, J. Bacardit, V.M. Rivas, J.C. Fernández, F. Herrera.
KEEL: A Software Tool to Assess Evolutionary Algorithms to Data Mining Problems.
Soft Computing 13:3 (2009) 307-318, doi: 10.1007/s00500-008-0323-y.

- J. Alcalá-Fdez, A. Fernandez, J. Luengo, J. Derrac, S. García, L. Sánchez, F. Herrera.
KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework.
Journal of Multiple-Valued Logic and Soft Computing 17:2-3 (2011) 255-287.
|
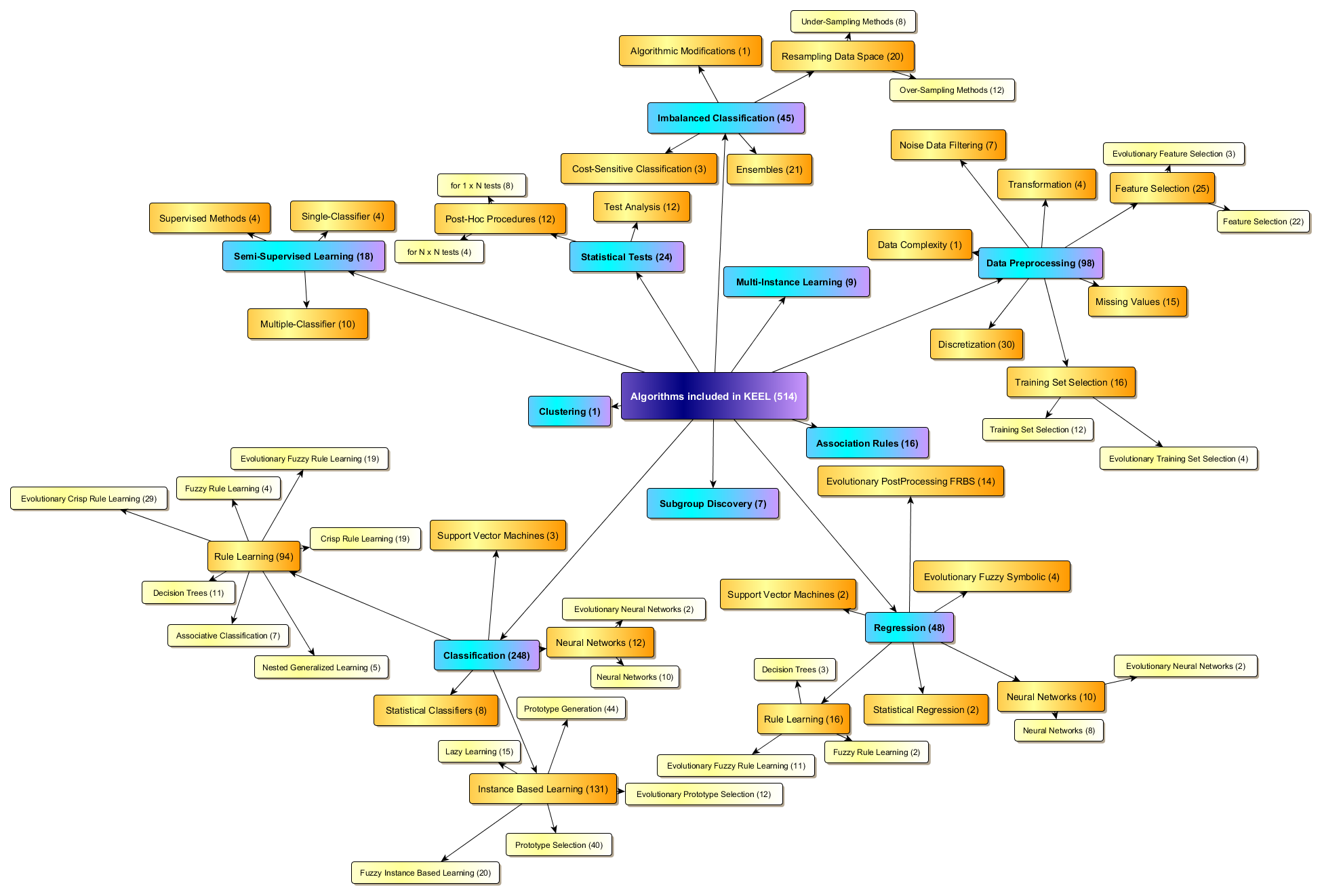
KEEL comprises a vast variety of algorithms, categorized in several families, as shown in the following scheme.
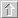 KEEL description
KEEL description
KEEL is a software tool to assess EAs for DM problems including regression,
classification, clustering, pattern mining and so on. The version of KEEL
presently available consists of the following function blocks:
- Data Management
This part is composed by a set of
tools that can be used to build new data, export and import data
in other formats to KEEL format, data edition and visualization, apply
transformations and partitioning to data, etc...
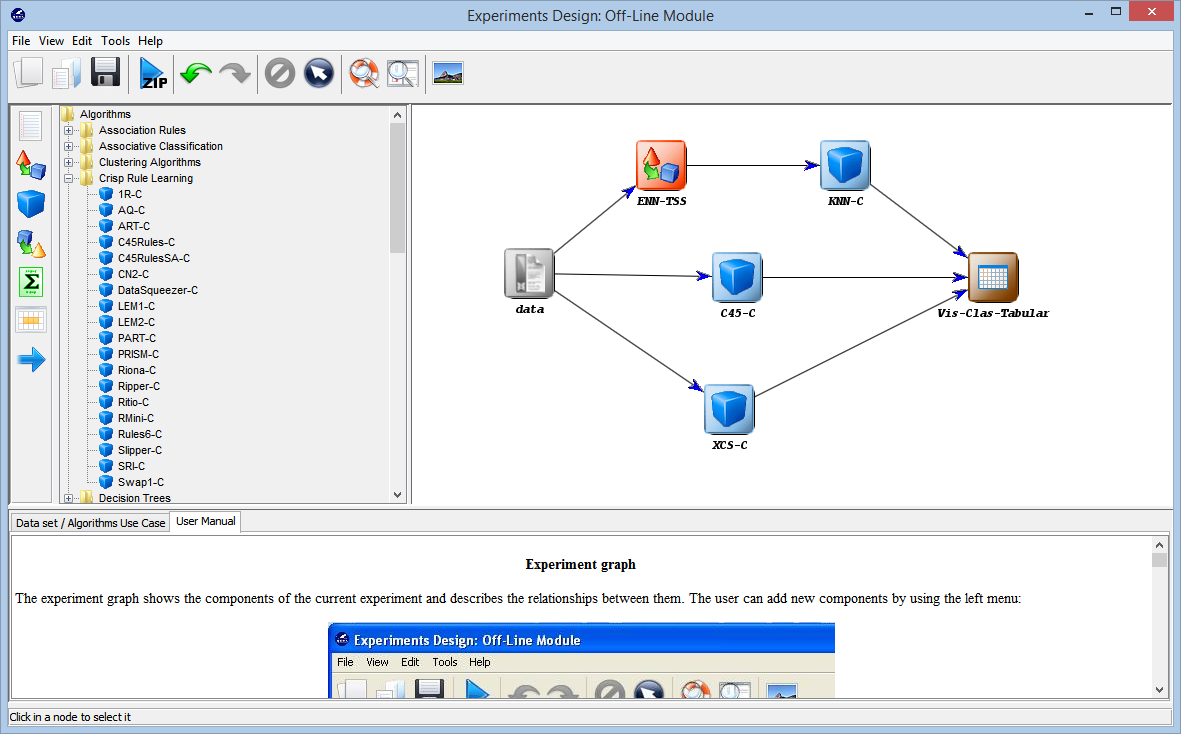
- Design of Experiments
The aim of this part is the
design of the desired experimentation over the selected data
sets. It provides options for many choices: type of validation,
type of learning (classification, regression, unsupervised
learning, subgroup discovery), etc...
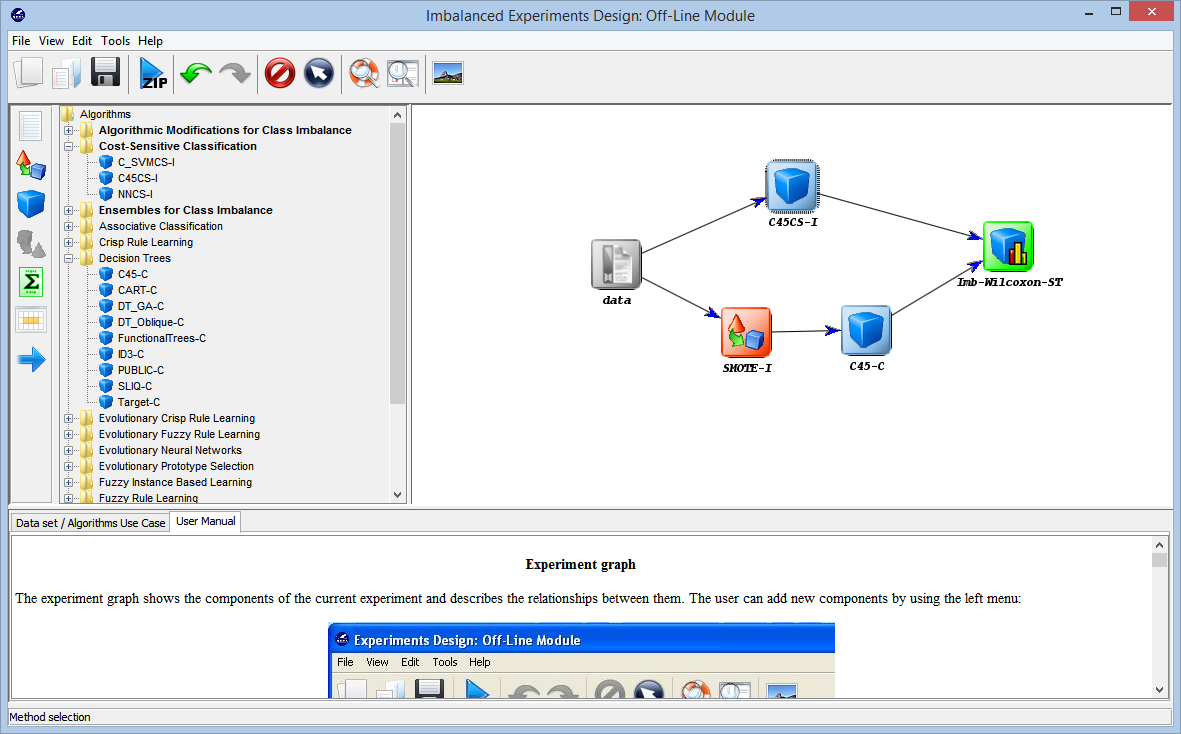
- Design of Imbalanced Experiments
The aim of this part is the
design of the desired experimentation over the selected imbalanced data
sets. These experiments are created for 5cfv datasets and include specific
algorithms for imbalanced data and general classification algorithms.
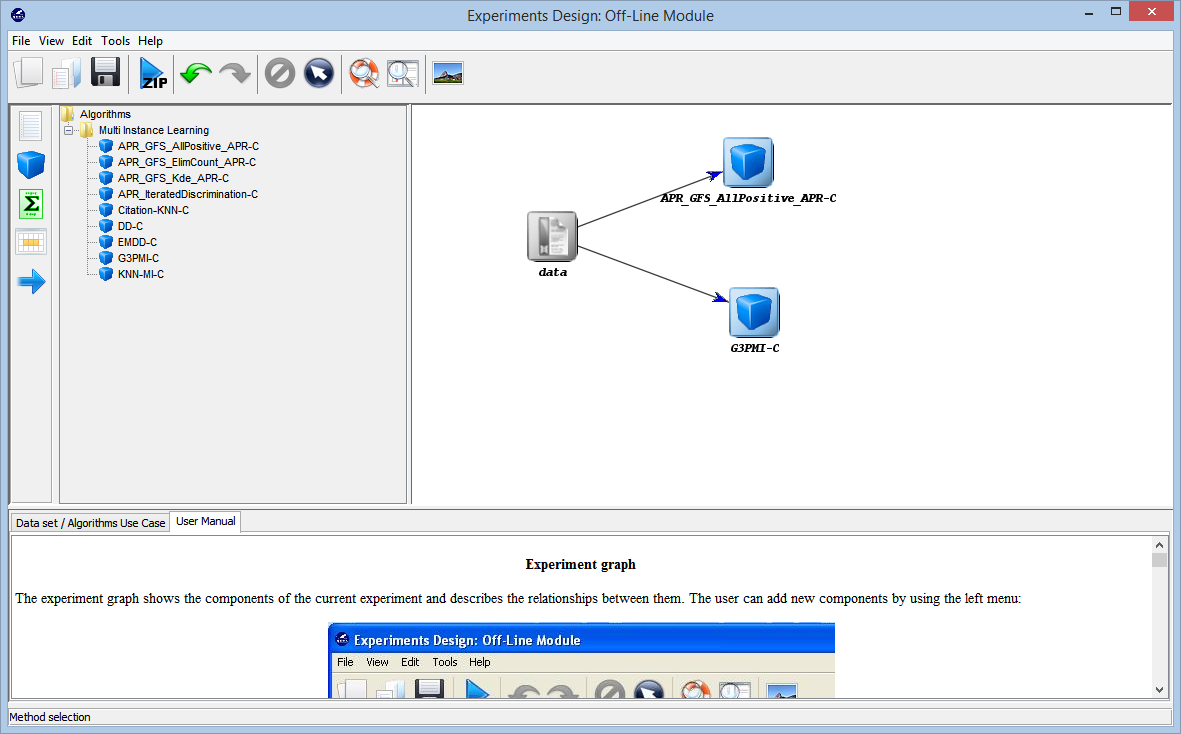
- Experimentation with Multiple Instance Learning Algorithms
In this section any researcher is able to address classification with multiple instance datasets.
In this case, instead of receiving a set of instances which are labeled positive or negative, the learner receives a set of bags, with multiple instances, that are labeled positive or negative.
The most common assumption is that a bag is labeled negative if all the instances in it are negative. On the other hand, a bag is labeled positive if there is at least one instance in it which is positive.
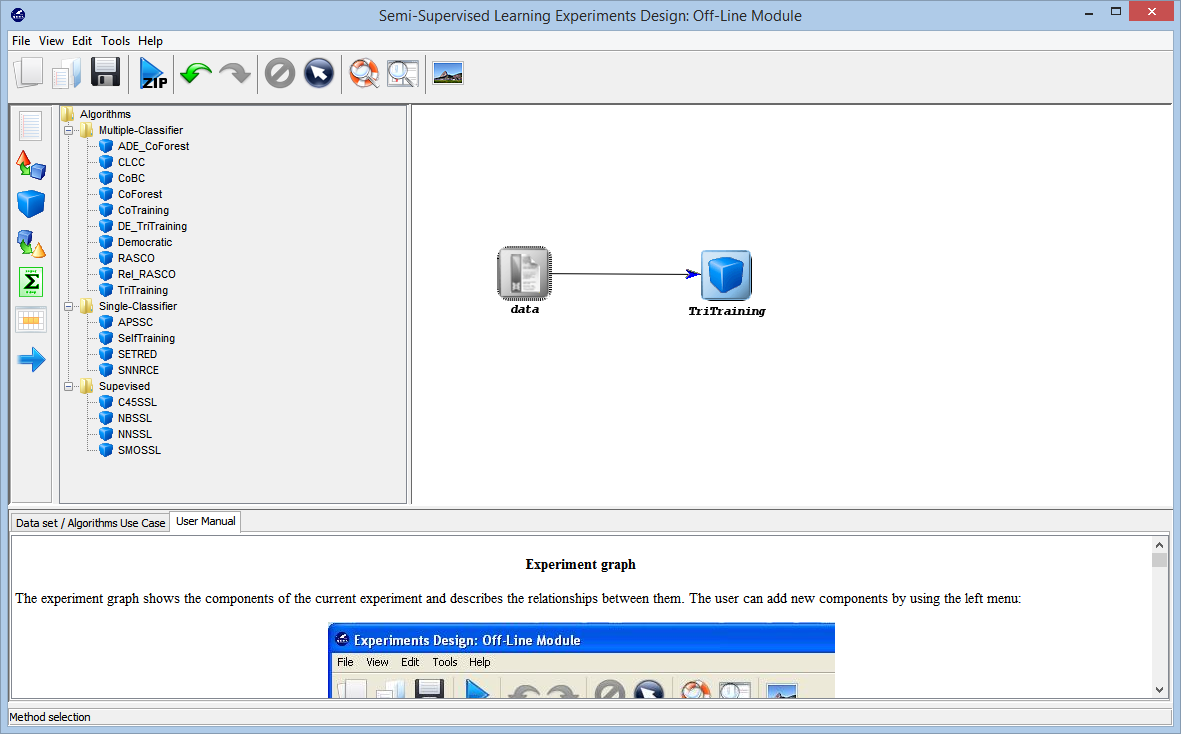
- Experimentation with Semi-supervised Learning Algorithms
In this section any researcher is able to address classification with semi-supervised learning datasets.
In this case, the learner works with both unlabeled and labeled examples and it can be used to perform both a transductive and inductive classification. The former concerns the problem of predicting the labels of the unlabeled examples, given in advance (in the training set), by taking both labeled and unlabeled data together into account to train a classifier. The latter considers the given labeled and unlabeled data as the training examples, and its objective is to predict unseen data.
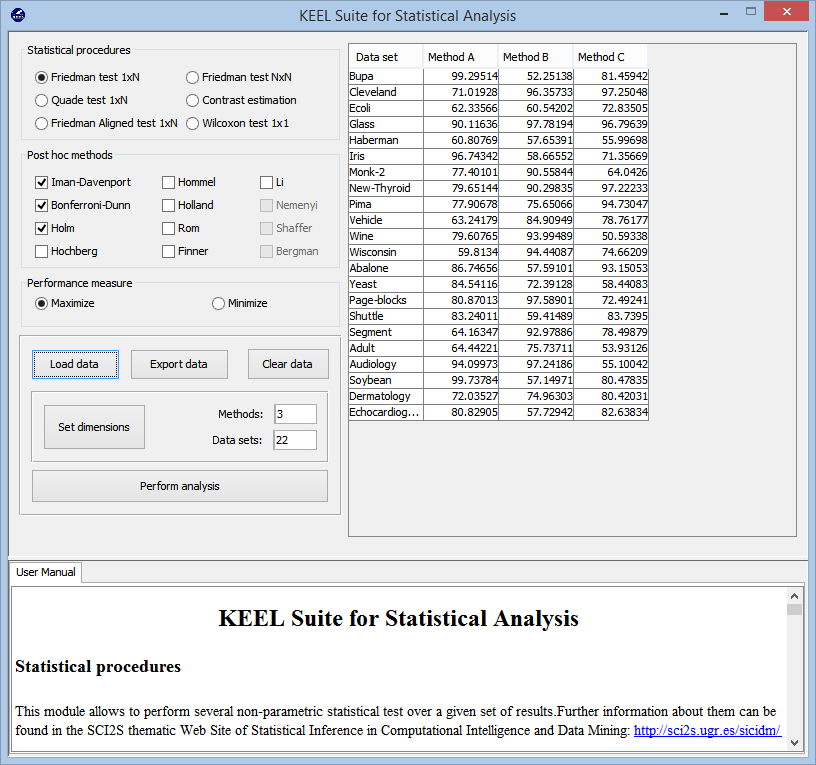
- Statistical Tests
KEEL is one of the fewest Data Mining software tools that provides to the
researcher a complete set of statistical procedures for pairwise and multiple comparisons. Inside the KEEL environment, several parametric and nonparametric
procedures have been coded, which should help to contrast the results obtained in any experiment performed with the software tool.
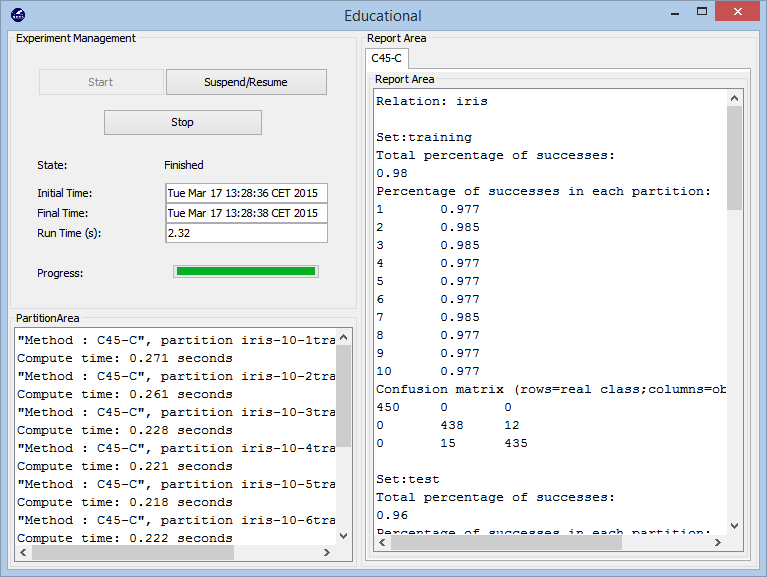
- Educational Experiments
With a similar structure to the Design of Experimets part, allows us to design an experiment which can
be step-by-step debugged in order to use this as a guideline to show the learning process of a certain model by using the
platform with educational objectives.
Taking into account each one of the function blocks, KEEL can be
useful by different types of user, which expect to find determined
features in a Data Mining (DM) software.
In the following, we describe the user profiles who it is designed
for, its main features and the different ways of working integrated in
the software tool.
User Profiles
KEEL is an integration of an environment with a
defined architecture and a development of knowledge extraction as
expandable modules. It is mainly intended for two categories of
users: researchers and students. Either group has a different set
of needs:
- KEEL as a research tool
The most common use of this tool for a researcher will be the
automated execution of experiments, and the statistical analysis of their results. Routinely, an experimental design includes a mix of
evolutionary algorithms, statistical and AI-related techniques. Special care was taken to make possible that a researcher can use
KEEL to assess the relevance of his own procedures. Since the actual standards in machine learning require heavy computational work, the
research tool is not designed to offer a real-time view of the progress of the algorithms, it is designed to rather generate a script and be
batch-executed in a cluster of computers. The tool allows the researcher to apply the same sequence of pre-processing, experiments
and analysis to large batteries of problems and focus his attention in the summary of the results.
- KEEL as an educational tool
The needs of a student are quite different
to those of a researcher. Generally speaking, the objective is no longer that of making statistically sound
comparisons between algorithms. There is no need of repeating each experiment a large number of times.
If the tool is to be used in class, the execution time must be short and a real-time view of the evolution
of the algorithms is needed, since the student will use this information to learn how to adjust the parameters
of the algorithms. In this sense, the educational tool is a simplified version of the research tool, where
only the most relevant algorithms are available. The execution is made in real time. The user has
a visual feedback of the progress of the algorithms, and can access the final results from the same interface
used to design the experimentation.
Both types of user require an availability of a set of features in
order to be interested in using KEEL. Then, this is when we
describe the main features of the KEEL software tool.
Main Features
KEEL is a software tool developed to ensemble and use different
DM models. We would like to remark that this is the first software
toolkit of this type containing a library of evolutionary learning
algorithms with open source code in Java. The main features of KEEL
are:
- Evolutionary Algorithms (EAs) are presented in predicting models,
pre-processing (evolutionary
feature and training set selection) and post-processing
(evolutionary tuning of fuzzy rules).
- It includes data pre-processing algorithms proposed in
specialized literature: data transformation, discretization, training set selection,
feature selection, imputation methods for missing values and noisy data filtering methods.
- It has a statistical library to analyze
algorithms' results. It comprises a set of statistical tests for
analyzing the normality and heteroscedasticity of the results
and performing parametric and non-parametric comparisons among
the algorithms.
- Some algorithms have been developed by using a Java Class Library for Evolutionary
Computation (JCLEC)
- It provides an user-friendly interface, oriented to
the analysis of algorithms.
- The software is aimed to create experimentations
containing multiple data sets and algorithms connected among
themselves to obtain a result expected. Experiments are
independently script-generated from the user interface for an off-line
run in the same or other machines.
- KEEL also allows to create experiments in on-line mode, aiming an educational support in order to learn the operation of the
algorithms included.
- It contains a Knowledge Extraction Algorithms
Library, remarking the incorporation of multiple evolutionary
learning algorithms, together with classical learning approaches. The main employment lines are:
- Different evolutionary rule learning models have been
implemented
- Fuzzy rule learning models with a good trade-off between
accuracy and interpretability.
- Evolution and pruning
in neural networks, product unit neural networks, and radial
base models.
- Genetic Programming: Evolutionary algorithms that
use tree representations for extracting knowledge.
- Algorithms for extracting
descriptive rules based on patterns subgroup discovery have been
integrated.
- Data reduction (training set selection, feature selection and discretization).
EAs for data reduction have been included.
|